options(readr.show_col_types=FALSE) # supress column type messages
pacman::p_load(tidyverse)
pacman::p_load(ggthemes)13 Human Computer Interaction Experiments
Following are my course notes from a 2018 Coursera course called Designing, Running, and Analyzing Experiments, taught by Jacob Wobbrock, a prominent HCI scholar. Note that Wobbrock is in no way responsible for any errors or deviations from his presentation.
These course notes are an example of reproducible research and literate programming. They are reproducible research because the same file that generated this html document also ran all the experiments. This is an example of literate programming in the sense that the code, pictures, equations, and narrative are all encapsulated in one file. The source file for this project, along with the data files, are enough for you to reproduce the results and reproduce the documentation. All the source material is available in my github account, although in an obscure location therein.
13.1 How many prefer this over that? (Tests of proportions)
13.1.1 How many prefer website A over B? (One sample test of proportions in two categories)
Sixty subjects were asked whether they preferred website A or B. Their answer and a subject ID were recorded. Read the data and describe it.
prefsAB <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/prefsAB.csv"))
tail(prefsAB) # displays the last few rows of the data frame# A tibble: 6 × 2
Subject Pref
<dbl> <chr>
1 55 A
2 56 B
3 57 A
4 58 B
5 59 B
6 60 A prefsAB$Subject <- factor(prefsAB$Subject) # convert to nominal factor
prefsAB$Pref <- factor(prefsAB$Pref) # convert to nominal factor
summary(prefsAB) Subject Pref
1 : 1 A:14
2 : 1 B:46
3 : 1
4 : 1
5 : 1
6 : 1
(Other):54 ggplot(prefsAB,aes(Pref)) +
geom_bar(width=0.5,alpha=0.4,fill="lightskyblue1") +
theme_tufte(base_size=7)
Is the difference between preferences significant? A default \(\chi^2\) test examines the proportions in two bins, expecting them to be equally apportioned.
To do the \(\chi^2\) test, first crosstabulate the data with xtabs().
#. Pearson chi-square test
prfs <- xtabs( ~ Pref, data=prefsAB)
prfs # show countsPref
A B
14 46 chisq.test(prfs)
Chi-squared test for given probabilities
data: prfs
X-squared = 17.067, df = 1, p-value = 3.609e-05We don’t really need an exact binomial test yet because the \(\chi^2\) test told us enough: that the difference is not likely due to chance. That was only because there are only two choices. If there were more than two, we’d need a binomial test for every pair if the \(\chi^2\) test turned up a significant difference. This binomial test just foreshadows what we’ll need when we face three categories.
#. binomial test
#. binom.test(prfs,split.table=Inf)
binom.test(prfs)
Exact binomial test
data: prfs
number of successes = 14, number of trials = 60, p-value = 4.224e-05
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.1338373 0.3603828
sample estimates:
probability of success
0.2333333 13.1.2 How many prefer website A, B, or C? (One sample test of proportions in three categories)
First, read in and describe the data. Convert Subject to a factor because R reads any numerical data as, well, numeric, but we don’t want to treat it as such. R interprets any data with characters as a factor. We want Subject to be treated as a factor.
prefsABC <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/prefsABC.csv"))
head(prefsABC) # displays the first few rows of the data frame# A tibble: 6 × 2
Subject Pref
<dbl> <chr>
1 1 C
2 2 C
3 3 B
4 4 C
5 5 C
6 6 B prefsABC$Subject <- factor(prefsABC$Subject)
prefsABC$Pref <- factor(prefsABC$Pref)
summary(prefsABC) Subject Pref
1 : 1 A: 8
2 : 1 B:21
3 : 1 C:31
4 : 1
5 : 1
6 : 1
(Other):54 par(pin=c(2.75,1.25),cex=0.5)
ggplot(prefsABC,aes(Pref))+
geom_bar(width=0.5,alpha=0.4,fill="lightskyblue1")+
theme_tufte(base_size=7)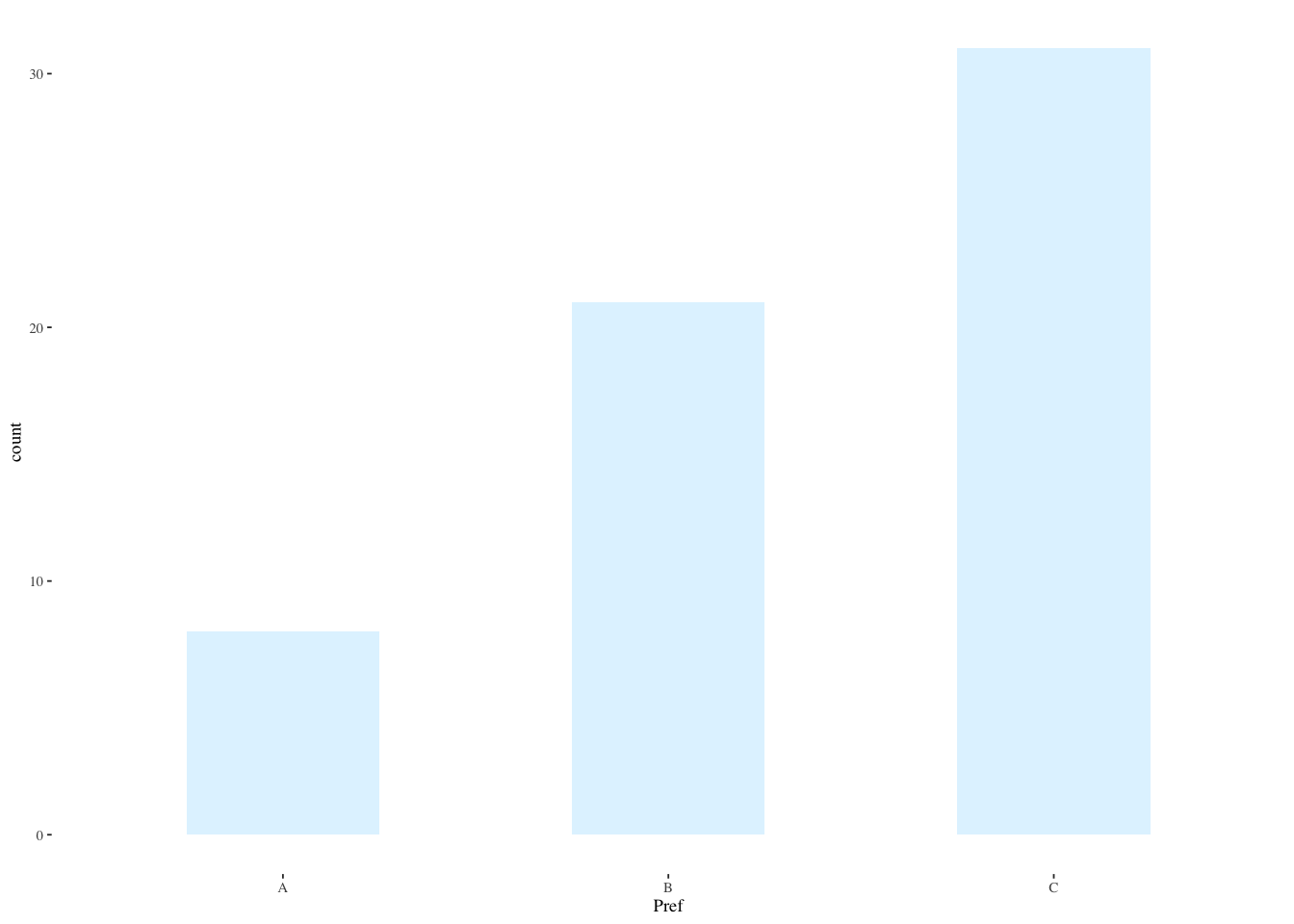
You can think of the three websites as representing three bins and the preferences as filling up those bins. Either each bin gets one third of the preferences or there is a discrepancy. The Pearson \(\chi^2\) test functions as an omnibus test to tell whether there is any discrepancy in the proportions of the three bins.
prfs <- xtabs( ~ Pref, data=prefsABC)
prfs # show countsPref
A B C
8 21 31 chisq.test(prfs)
Chi-squared test for given probabilities
data: prfs
X-squared = 13.3, df = 2, p-value = 0.001294A multinomial test can test for other than an even distribution across bins. Here’s an example with a one third distribution in each bin.
pacman::p_load(XNomial)
xmulti(prfs, c(1/3, 1/3, 1/3), statName="Prob")
P value (Prob) = 0.0008024Now we don’t know which pair(s) differed so it makes sense to conduct post hoc binomial tests with correction for multiple comparisons. The correction, made by p.adjust(), is because the more hypotheses we check, the higher the probability of a Type I error, a false positive. That is, the more hypotheses we test, the higher the probability that one will appear true by chance. Wikipedia has more detail in its “Multiple Comparisons Problem” article.
Here, we test separately for whether each one has a third of the preferences.
aa <- binom.test(sum(prefsABC$Pref == "A"),
nrow(prefsABC), p=1/3)
bb <- binom.test(sum(prefsABC$Pref == "B"),
nrow(prefsABC), p=1/3)
cc <- binom.test(sum(prefsABC$Pref == "C"),
nrow(prefsABC), p=1/3)
p.adjust(c(aa$p.value, bb$p.value, cc$p.value), method="holm")[1] 0.001659954 0.785201685 0.007446980The adjusted \(p\)-values tell us that A and C differ significantly from a third of the preferences.
13.1.3 How many males vs females prefer website A over B? (Two-sample tests of proportions in two categories)
Revisit our data file with 2 response categories, but now with sex (M/F).
prefsABsex <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/prefsABsex.csv"))
tail(prefsABsex)# A tibble: 6 × 3
Subject Pref Sex
<dbl> <chr> <chr>
1 55 A M
2 56 B F
3 57 A M
4 58 B M
5 59 B M
6 60 A M prefsABsex$Subject <- factor(prefsABsex$Subject)
prefsABsex$Pref <- factor(prefsABsex$Pref)
prefsABsex$Sex <- factor(prefsABsex$Sex)
summary(prefsABsex) Subject Pref Sex
1 : 1 A:14 F:31
2 : 1 B:46 M:29
3 : 1
4 : 1
5 : 1
6 : 1
(Other):54 Plotting is slightly more complicated by the fact that we want to represent two groups. There are many ways to do this, including stacked bar charts, side-by-side bars, or the method chosen here, using facet_wrap(~Sex) to cause two separate plots based on Sex to be created.
ggplot(prefsABsex,aes(Pref)) +
geom_bar(width=0.5,alpha=0.4,fill="lightskyblue1") +
facet_wrap(~Sex) +
theme_tufte(base_size=7)
Although we can guess by looking at the above plot that the difference for females is significant and the difference for males is not, a Pearson chi-square test provides some statistical evidence for this hunch.
prfs <- xtabs( ~ Pref + Sex, data=prefsABsex) # the '+' sign indicates two vars
prfs Sex
Pref F M
A 2 12
B 29 17chisq.test(prfs)
Pearson's Chi-squared test with Yates' continuity correction
data: prfs
X-squared = 8.3588, df = 1, p-value = 0.00383813.1.4 What if the data are lopsided? (G-test, alternative to chi-square)
Wikipedia tells us that the \(G\)-test dominates the \(\chi^2\) test when \(O_i>2E_i\) in the formula
\[\chi^2=\sum_i \frac{(O_i-E_i)^2}{E_i}\]
where \(O_i\) is the observed and \(E_i\) is the expected proportion in the \(i\)th bin. This situation may occur in small sample sizes. For large sample sizes, both tests give the same conclusion. In our case, we’re on the borderline for this rule in the bin where 29 females prefer B. All females would have to prefer B for the rule to dictate a switch to the \(G\)-test.
pacman::p_load(RVAideMemoire)
G.test(prfs)
G-test
data: prfs
G = 11.025, df = 1, p-value = 0.0008989#. Fisher's exact test
fisher.test(prfs)
Fisher's Exact Test for Count Data
data: prfs
p-value = 0.001877
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.009898352 0.537050159
sample estimates:
odds ratio
0.1015763 13.1.5 How many males vs females prefer website A, B, or C? (Two-sample tests of proportions in three categories)
Revisit our data file with 3 response categories, but now with sex (M/F).
prefsABCsex <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/prefsABCsex.csv"))
head(prefsABCsex)# A tibble: 6 × 3
Subject Pref Sex
<dbl> <chr> <chr>
1 1 C F
2 2 C M
3 3 B M
4 4 C M
5 5 C M
6 6 B F prefsABCsex$Subject <- factor(prefsABCsex$Subject)
prefsABCsex$Pref <- factor(prefsABCsex$Pref)
prefsABCsex$Sex <- factor(prefsABCsex$Sex)
summary(prefsABCsex) Subject Pref Sex
1 : 1 A: 8 F:29
2 : 1 B:21 M:31
3 : 1 C:31
4 : 1
5 : 1
6 : 1
(Other):54 ggplot(prefsABCsex,aes(Pref)) +
geom_bar(width=0.5,alpha=0.4,fill="lightskyblue1") +
facet_wrap(~Sex) +
theme_tufte(base_size=7)
#. Pearson chi-square test
prfs <- xtabs( ~ Pref + Sex, data=prefsABCsex)
prfs Sex
Pref F M
A 3 5
B 15 6
C 11 20chisq.test(prfs)Warning in chisq.test(prfs): Chi-squared approximation may be incorrect
Pearson's Chi-squared test
data: prfs
X-squared = 6.9111, df = 2, p-value = 0.03157#. G-test
G.test(prfs)
G-test
data: prfs
G = 7.0744, df = 2, p-value = 0.02909#. Fisher's exact test
fisher.test(prfs)
Fisher's Exact Test for Count Data
data: prfs
p-value = 0.03261
alternative hypothesis: two.sidedNow conduct manual post hoc binomial tests for (m)ales—do any prefs for A–C significantly differ from chance for males?
ma <- binom.test(sum(prefsABCsex[prefsABCsex$Sex == "M",]$Pref == "A"),
nrow(prefsABCsex[prefsABCsex$Sex == "M",]), p=1/3)
mb <- binom.test(sum(prefsABCsex[prefsABCsex$Sex == "M",]$Pref == "B"),
nrow(prefsABCsex[prefsABCsex$Sex == "M",]), p=1/3)
mc <- binom.test(sum(prefsABCsex[prefsABCsex$Sex == "M",]$Pref == "C"),
nrow(prefsABCsex[prefsABCsex$Sex == "M",]), p=1/3)
#. correct for multiple comparisons
p.adjust(c(ma$p.value, mb$p.value, mc$p.value), method="holm")[1] 0.109473564 0.126622172 0.001296754Next, conduct manual post hoc binomial tests for (f)emales—do any prefs for A–C significantly differ from chance for females?
fa <- binom.test(sum(prefsABCsex[prefsABCsex$Sex == "F",]$Pref == "A"),
nrow(prefsABCsex[prefsABCsex$Sex == "F",]), p=1/3)
fb <- binom.test(sum(prefsABCsex[prefsABCsex$Sex == "F",]$Pref == "B"),
nrow(prefsABCsex[prefsABCsex$Sex == "F",]), p=1/3)
fc <- binom.test(sum(prefsABCsex[prefsABCsex$Sex == "F",]$Pref == "C"),
nrow(prefsABCsex[prefsABCsex$Sex == "F",]), p=1/3)
#. correct for multiple comparisons
p.adjust(c(fa$p.value, fb$p.value, fc$p.value), method="holm")[1] 0.02703274 0.09447821 0.6939695113.2 How do groups compare in reading performance? (Independent samples \(t\)-test)
Here we are asking which group read more pages on a particular website.
pgviews <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/pgviews.csv"))
pgviews$Subject <- factor(pgviews$Subject)
pgviews$Site <- factor(pgviews$Site)
summary(pgviews) Subject Site Pages
1 : 1 A:245 Min. : 1.000
2 : 1 B:255 1st Qu.: 3.000
3 : 1 Median : 4.000
4 : 1 Mean : 3.958
5 : 1 3rd Qu.: 5.000
6 : 1 Max. :11.000
(Other):494 tail(pgviews)# A tibble: 6 × 3
Subject Site Pages
<fct> <fct> <dbl>
1 495 A 3
2 496 B 6
3 497 B 6
4 498 A 3
5 499 A 4
6 500 B 6#. descriptive statistics by Site
plyr::ddply(pgviews, ~ Site, function(data) summary(data$Pages)) Site Min. 1st Qu. Median Mean 3rd Qu. Max.
1 A 1 3 3 3.404082 4 6
2 B 1 3 4 4.490196 6 11plyr::ddply(pgviews, ~ Site, summarise, Pages.mean=mean(Pages), Pages.sd=sd(Pages)) Site Pages.mean Pages.sd
1 A 3.404082 1.038197
2 B 4.490196 2.127552#. graph histograms and a boxplot
ggplot(pgviews,aes(Pages,fill=Site,color=Site)) +
geom_bar(alpha=0.5,position="identity",color="white") +
scale_color_grey() +
scale_fill_grey() +
theme_tufte(base_size=7)
ggplot(pgviews,aes(Site,Pages,fill=Site)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=7)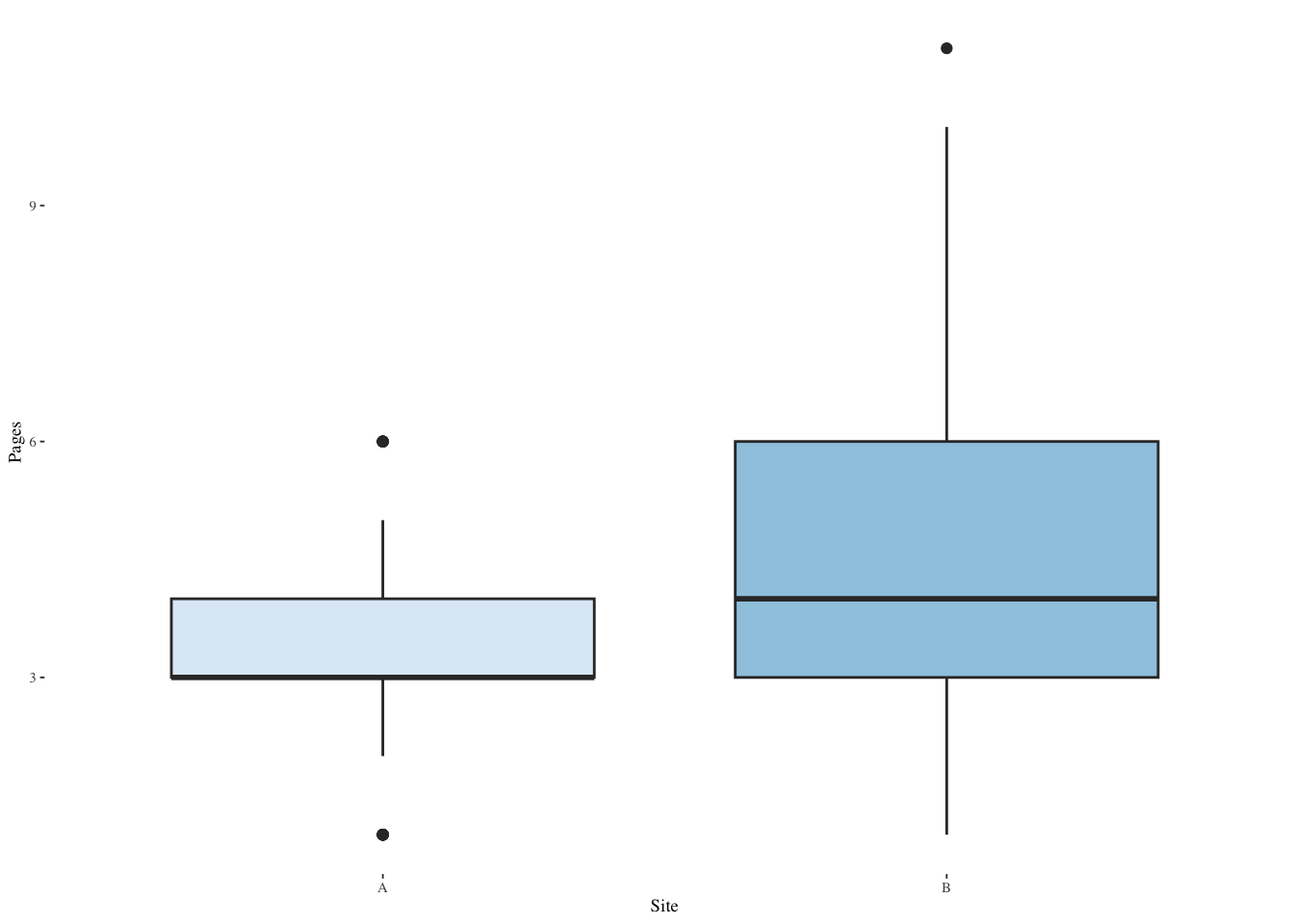
#. independent-samples t-test
t.test(Pages ~ Site, data=pgviews, var.equal=TRUE)
Two Sample t-test
data: Pages by Site
t = -7.2083, df = 498, p-value = 2.115e-12
alternative hypothesis: true difference in means between group A and group B is not equal to 0
95 percent confidence interval:
-1.3821544 -0.7900745
sample estimates:
mean in group A mean in group B
3.404082 4.490196 13.3 ANOVA
ANOVA stands for analysis of variance and is a way to generalize the \(t\)-test to more groups.
13.3.1 How long does it take to perform tasks on two IDEs?
ide2 <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/ide2.csv"))
ide2$Subject <- factor(ide2$Subject) # convert to nominal factor
ide2$IDE <- factor(ide2$IDE) # convert to nominal factor
summary(ide2) Subject IDE Time
1 : 1 Eclipse:20 Min. :155.0
2 : 1 VStudio:20 1st Qu.:271.8
3 : 1 Median :313.5
4 : 1 Mean :385.1
5 : 1 3rd Qu.:422.0
6 : 1 Max. :952.0
(Other):34 #. view descriptive statistics by IDE
plyr::ddply(ide2, ~ IDE, function(data) summary(data$Time)) IDE Min. 1st Qu. Median Mean 3rd Qu. Max.
1 Eclipse 232 294.75 393.5 468.15 585.50 952
2 VStudio 155 246.50 287.0 302.10 335.25 632plyr::ddply(ide2, ~ IDE, summarise, Time.mean=mean(Time), Time.sd=sd(Time)) IDE Time.mean Time.sd
1 Eclipse 468.15 218.1241
2 VStudio 302.10 101.0778#. graph histograms and a boxplot
ggplot(ide2,aes(Time,fill=IDE)) +
geom_histogram(binwidth=50,position=position_dodge()) +
scale_fill_brewer(palette="Paired") +
theme_tufte(base_size=7)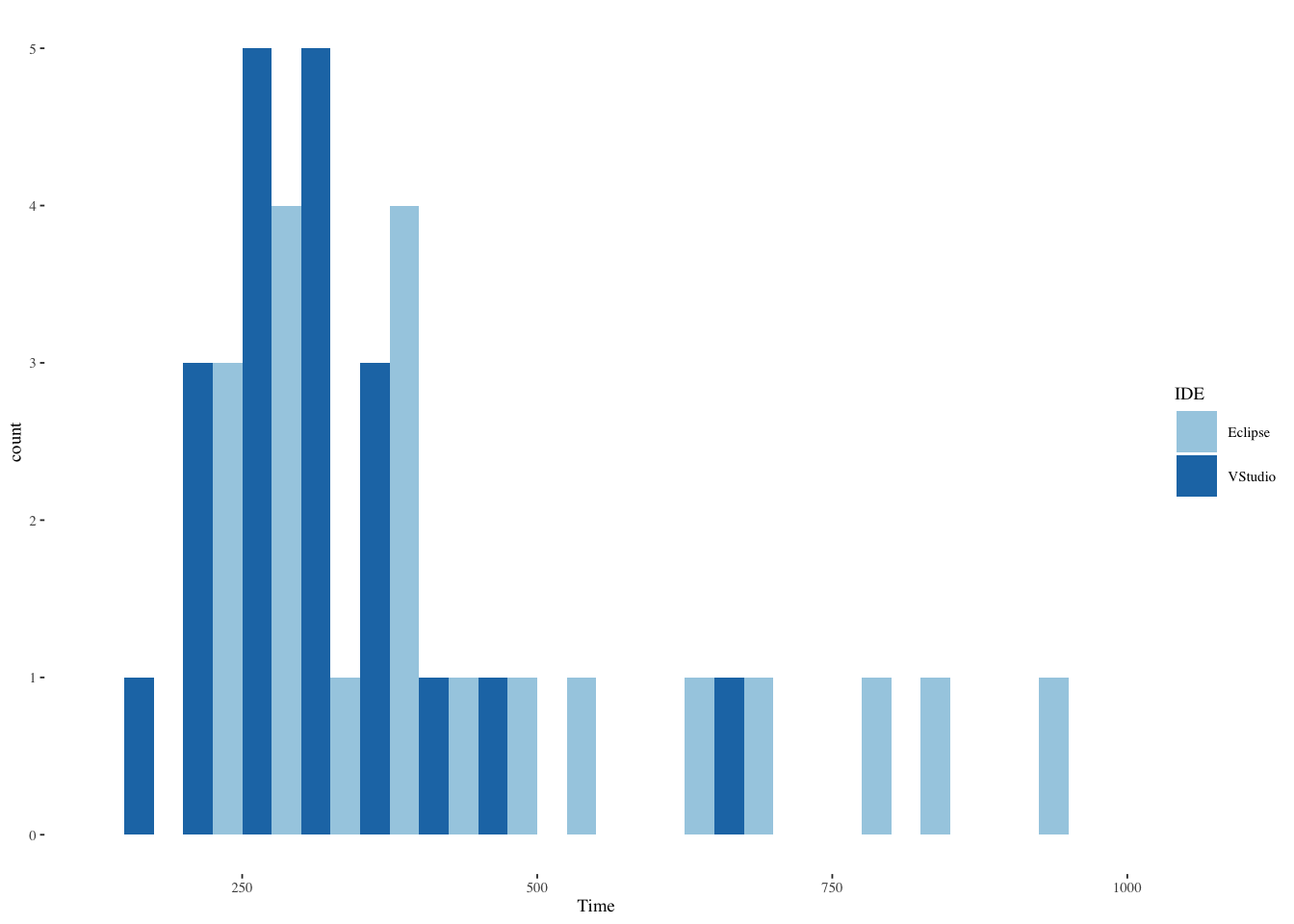
ggplot(ide2,aes(IDE,Time,fill=IDE)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=7)
#. independent-samples t-test (suitable? maybe not, because...)
t.test(Time ~ IDE, data=ide2, var.equal=TRUE)
Two Sample t-test
data: Time by IDE
t = 3.0889, df = 38, p-value = 0.003745
alternative hypothesis: true difference in means between group Eclipse and group VStudio is not equal to 0
95 percent confidence interval:
57.226 274.874
sample estimates:
mean in group Eclipse mean in group VStudio
468.15 302.10 13.3.2 Testing ANOVA assumptions
The null hypothesis of the Shapiro-Wilk test is that the data are drawn from a normal distribution. A small \(p\)-value indicates that they are not.
The null hypothesis of the Levene test (using means) and of the Brown-Forsythe test (using medians) is that the variances of the groups are the same. A small \(p\)-value indicates that the variances are not the same.
In all the above cases, a logarithmic transformation may solve the problem (both non-normality and unequal variances).
#. Shapiro-Wilk normality test on response
shapiro.test(ide2[ide2$IDE == "VStudio",]$Time)
Shapiro-Wilk normality test
data: ide2[ide2$IDE == "VStudio", ]$Time
W = 0.84372, p-value = 0.004191shapiro.test(ide2[ide2$IDE == "Eclipse",]$Time)
Shapiro-Wilk normality test
data: ide2[ide2$IDE == "Eclipse", ]$Time
W = 0.87213, p-value = 0.01281#. but really what matters most is the residuals
m = aov(Time ~ IDE, data=ide2) # fit model
shapiro.test(residuals(m)) # test residuals
Shapiro-Wilk normality test
data: residuals(m)
W = 0.894, p-value = 0.001285par(pin=c(2.75,1.25),cex=0.5)
qqnorm(residuals(m)); qqline(residuals(m)) # plot residuals
13.3.3 Kolmogorov-Smirnov test for log-normality
Fit the distribution to a log-normal to estimate fit parameters then supply those to a K-S test with the log-normal distribution fn (see ?plnorm). See ?distributions for many other named probability distributions.
The Kolmogorov-Smirnov test can be used with any continuous distribution function. Here, the specification of log-normal is given by the string with the name of the cumulative distribution function of the log-normal, specifically plnorm. (The Kolmogorov-Smirnov test is so frequently used with pnorm, the cumulative distribution function of the normal distribution, that it is often called the Kolmogorov-Smirnov normality test). The remainder of the function call gives the parameters of the log-normal distribution function, mean and standard deviation. The null hypothesis in this case is that the data are drawn from a log-normal distribution. A small \(p\)-value indicates that they are not.
pacman::p_load(MASS)
fit <- fitdistr(ide2[ide2$IDE == "VStudio",]$Time,
"lognormal")$estimate
ks.test(ide2[ide2$IDE == "VStudio",]$Time, "plnorm",
meanlog=fit[1], sdlog=fit[2], exact=TRUE)
Exact one-sample Kolmogorov-Smirnov test
data: ide2[ide2$IDE == "VStudio", ]$Time
D = 0.13421, p-value = 0.8181
alternative hypothesis: two-sidedfit <- fitdistr(ide2[ide2$IDE == "Eclipse",]$Time,
"lognormal")$estimate
ks.test(ide2[ide2$IDE == "Eclipse",]$Time, "plnorm",
meanlog=fit[1], sdlog=fit[2], exact=TRUE)
Exact one-sample Kolmogorov-Smirnov test
data: ide2[ide2$IDE == "Eclipse", ]$Time
D = 0.12583, p-value = 0.871
alternative hypothesis: two-sided#. tests for homoscedasticity (homogeneity of variance)
pacman::p_load(car)
leveneTest(Time ~ IDE, data=ide2, center=mean) # Levene's testLevene's Test for Homogeneity of Variance (center = mean)
Df F value Pr(>F)
group 1 11.959 0.001356 **
38
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1leveneTest(Time ~ IDE, data=ide2, center=median) # Brown-Forsythe testLevene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 5.9144 0.01984 *
38
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#. Welch t-test for unequal variances handles
#. the violation of homoscedasticity. but not
#. the violation of normality.
t.test(Time ~ IDE, data=ide2, var.equal=FALSE) # Welch t-test
Welch Two Sample t-test
data: Time by IDE
t = 3.0889, df = 26.8, p-value = 0.004639
alternative hypothesis: true difference in means between group Eclipse and group VStudio is not equal to 0
95 percent confidence interval:
55.71265 276.38735
sample estimates:
mean in group Eclipse mean in group VStudio
468.15 302.10 13.3.4 Data transformation
#. create a new column in ide2 defined as log(Time)
ide2$logTime <- log(ide2$Time) # log transform
head(ide2) # verify# A tibble: 6 × 4
Subject IDE Time logTime
<fct> <fct> <dbl> <dbl>
1 1 VStudio 341 5.83
2 2 VStudio 291 5.67
3 3 VStudio 283 5.65
4 4 VStudio 155 5.04
5 5 VStudio 271 5.60
6 6 VStudio 270 5.60#. explore for intuition-building
ggplot(ide2,aes(logTime,fill=IDE)) +
geom_histogram(binwidth=0.2,position=position_dodge()) +
scale_fill_brewer(palette="Paired") +
theme_tufte(base_size=7)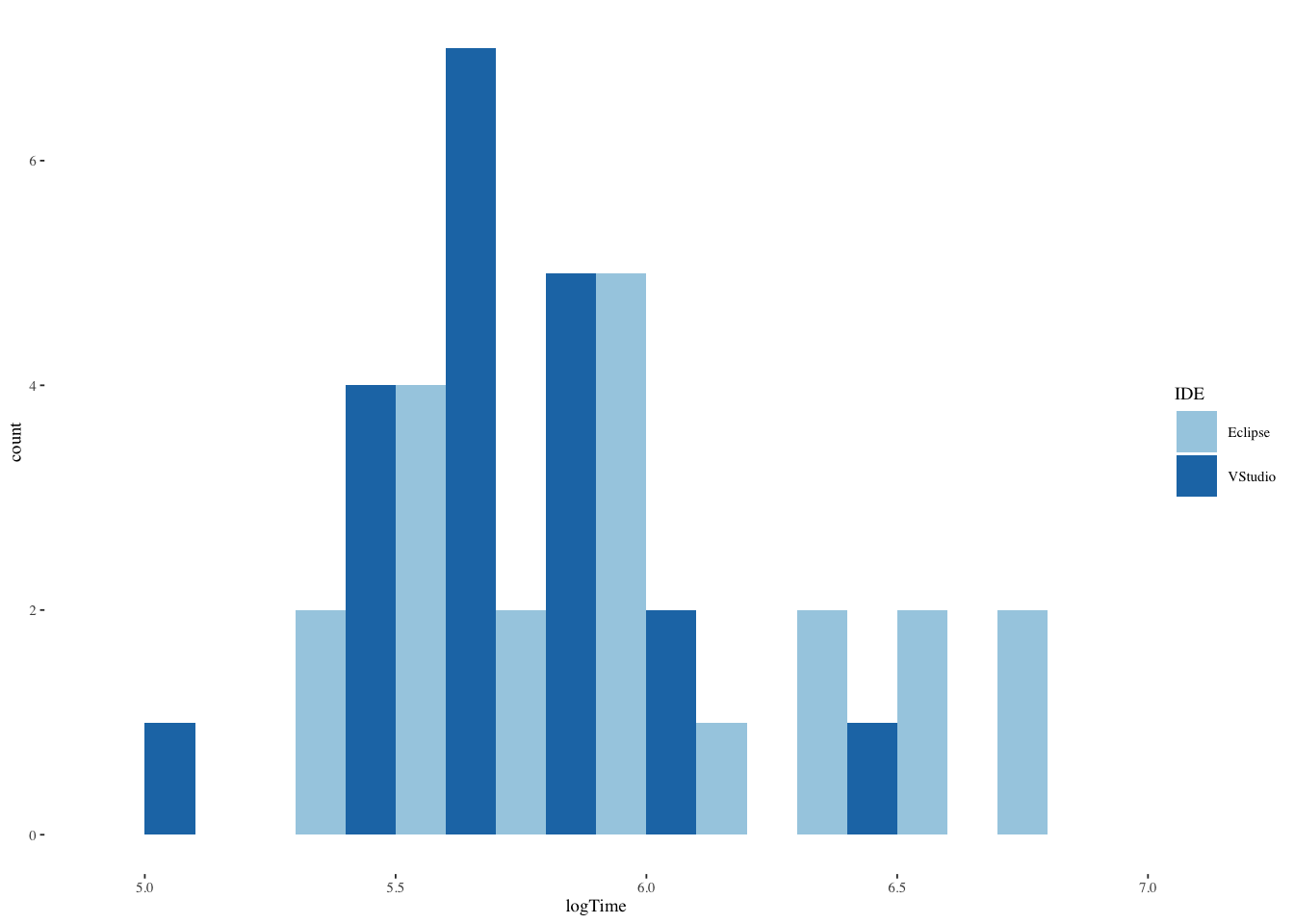
ggplot(ide2,aes(IDE,logTime,fill=IDE)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=7)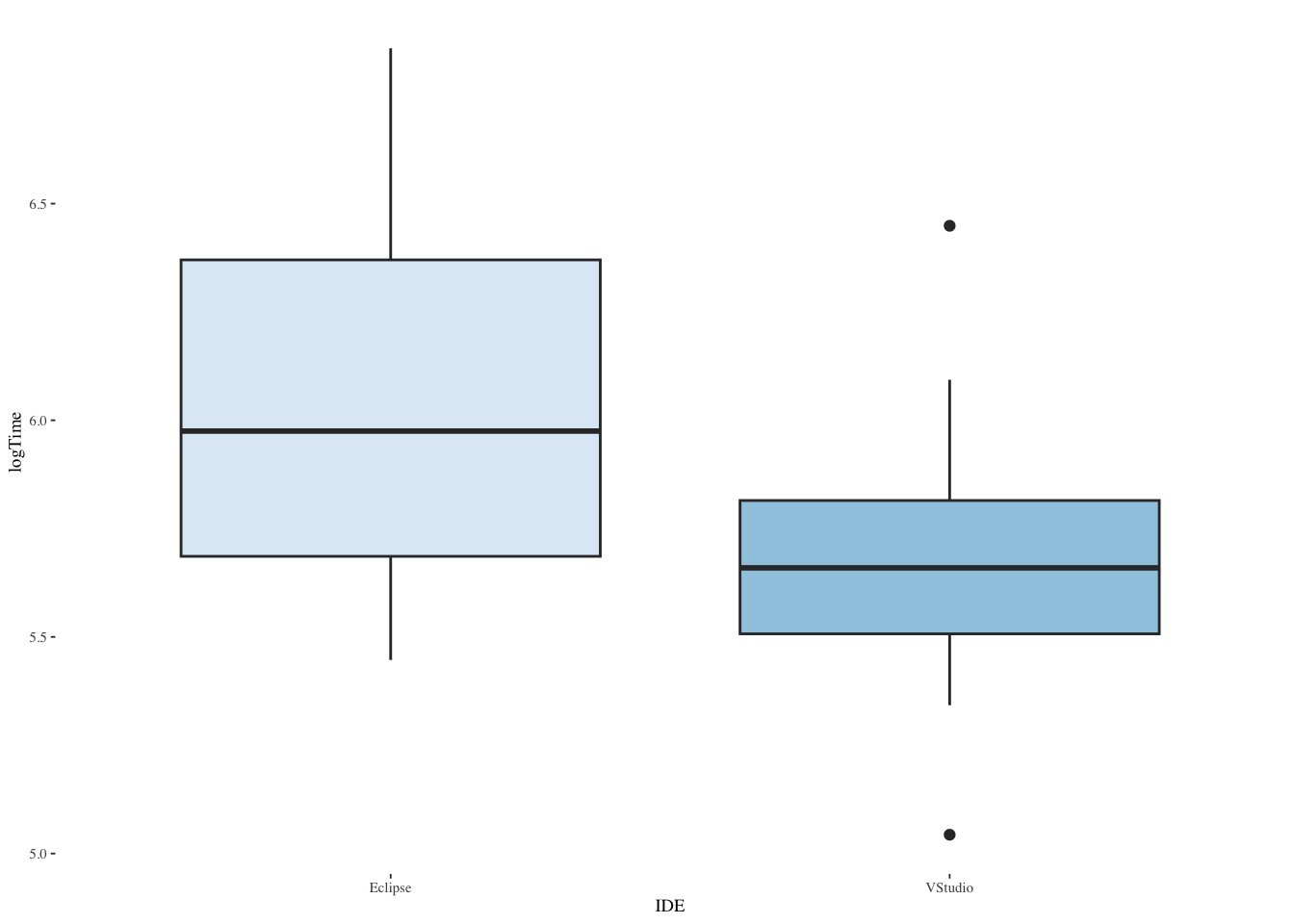
#. re-test for normality
shapiro.test(ide2[ide2$IDE == "VStudio",]$logTime)
Shapiro-Wilk normality test
data: ide2[ide2$IDE == "VStudio", ]$logTime
W = 0.95825, p-value = 0.5094shapiro.test(ide2[ide2$IDE == "Eclipse",]$logTime)
Shapiro-Wilk normality test
data: ide2[ide2$IDE == "Eclipse", ]$logTime
W = 0.93905, p-value = 0.23m <- aov(logTime ~ IDE, data=ide2) # fit model
shapiro.test(residuals(m)) # test residuals
Shapiro-Wilk normality test
data: residuals(m)
W = 0.96218, p-value = 0.1987par(pin=c(2.75,1.25),cex=0.5)
qqnorm(residuals(m)); qqline(residuals(m)) # plot residuals
#. re-test for homoscedasticity
leveneTest(logTime ~ IDE, data=ide2, center=median) # Brown-Forsythe testLevene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 3.2638 0.07875 .
38
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#. independent-samples t-test (now suitable for logTime)
t.test(logTime ~ IDE, data=ide2, var.equal=TRUE)
Two Sample t-test
data: logTime by IDE
t = 3.3121, df = 38, p-value = 0.002039
alternative hypothesis: true difference in means between group Eclipse and group VStudio is not equal to 0
95 percent confidence interval:
0.1514416 0.6276133
sample estimates:
mean in group Eclipse mean in group VStudio
6.055645 5.666118 13.3.5 What if ANOVA assumptions don’t hold? (Nonparametric equivalent of independent-samples t-test)
13.3.6 Mann-Whitney U test
This is a nonparametric test of the null hypothesis that, for randomly selected values from two populations, the probability of the first being greater than the second is equal to the probability of the second being greater than the first. A small \(p\)-value indicates that it is not. (The test is also called the Wilcoxon-Mann-Whitney test, hence the function name given below.)
pacman::p_load(coin)
wilcox_test(Time ~ IDE, data=ide2, distribution="exact")
Exact Wilcoxon-Mann-Whitney Test
data: Time by IDE (Eclipse, VStudio)
Z = 2.9487, p-value = 0.002577
alternative hypothesis: true mu is not equal to 0wilcox_test(logTime ~ IDE, data=ide2, distribution="exact") # note: same result
Exact Wilcoxon-Mann-Whitney Test
data: logTime by IDE (Eclipse, VStudio)
Z = 2.9487, p-value = 0.002577
alternative hypothesis: true mu is not equal to 013.3.7 How long does it take to do tasks on one of three tools? (One-way ANOVA preparation)
#. read in a data file with task completion times (min) now from 3 tools
ide3 <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/ide3.csv"))
ide3$Subject <- factor(ide3$Subject) # convert to nominal factor
ide3$IDE <- factor(ide3$IDE) # convert to nominal factor
summary(ide3) Subject IDE Time
1 : 1 Eclipse:20 Min. :143.0
2 : 1 PyCharm:20 1st Qu.:248.8
3 : 1 VStudio:20 Median :295.0
4 : 1 Mean :353.9
5 : 1 3rd Qu.:391.2
6 : 1 Max. :952.0
(Other):54 #. view descriptive statistics by IDE
plyr::ddply(ide3, ~ IDE, function(data) summary(data$Time)) IDE Min. 1st Qu. Median Mean 3rd Qu. Max.
1 Eclipse 232 294.75 393.5 468.15 585.50 952
2 PyCharm 143 232.25 279.5 291.45 300.00 572
3 VStudio 155 246.50 287.0 302.10 335.25 632plyr::ddply(ide3, ~ IDE, summarise, Time.mean=mean(Time), Time.sd=sd(Time)) IDE Time.mean Time.sd
1 Eclipse 468.15 218.1241
2 PyCharm 291.45 106.8922
3 VStudio 302.10 101.0778ide3 |>
group_by(IDE) |>
summarize(median=median(Time),mean=mean(Time),sd=sd(Time))# A tibble: 3 × 4
IDE median mean sd
<fct> <dbl> <dbl> <dbl>
1 Eclipse 394. 468. 218.
2 PyCharm 280. 291. 107.
3 VStudio 287 302. 101.#. explore new response distribution
ggplot(ide3,aes(Time,fill=IDE)) +
geom_histogram(binwidth=50,position=position_dodge()) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=7)
ggplot(ide3,aes(IDE,Time,fill=IDE)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=7)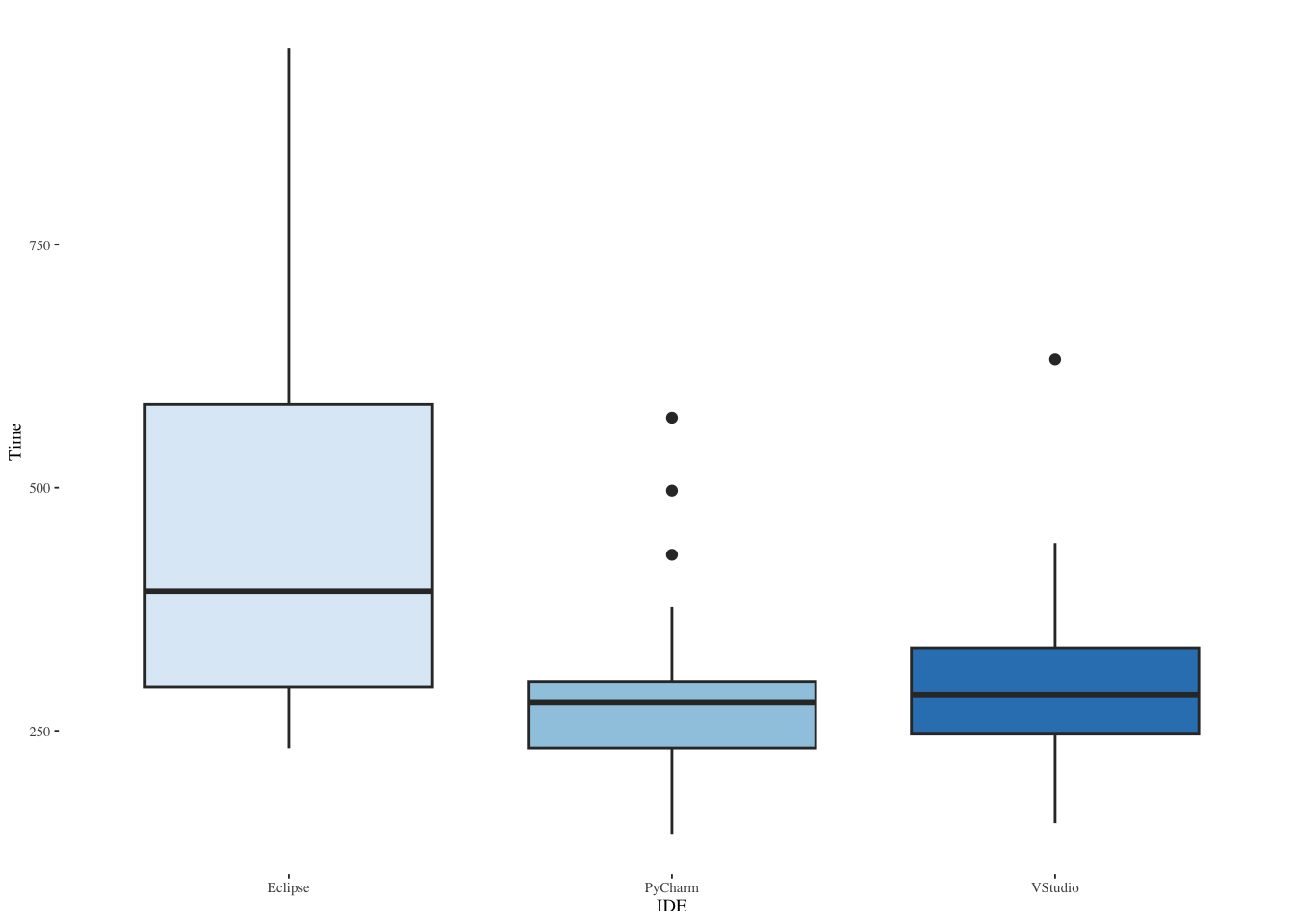
#. test normality for new IDE
shapiro.test(ide3[ide3$IDE == "PyCharm",]$Time)
Shapiro-Wilk normality test
data: ide3[ide3$IDE == "PyCharm", ]$Time
W = 0.88623, p-value = 0.02294m <- aov(Time ~ IDE, data=ide3) # fit model
shapiro.test(residuals(m)) # test residuals
Shapiro-Wilk normality test
data: residuals(m)
W = 0.89706, p-value = 0.000103par(pin=c(2.75,1.25),cex=0.5)
qqnorm(residuals(m)); qqline(residuals(m)) # plot residuals
#. test log-normality of new IDE
fit <- fitdistr(ide3[ide3$IDE == "PyCharm",]$Time, "lognormal")$estimate
ks.test(ide3[ide3$IDE == "PyCharm",]$Time,
"plnorm", meanlog=fit[1], sdlog=fit[2], exact=TRUE) # lognormality
Exact one-sample Kolmogorov-Smirnov test
data: ide3[ide3$IDE == "PyCharm", ]$Time
D = 0.1864, p-value = 0.4377
alternative hypothesis: two-sided#. compute new log(Time) column and re-test
ide3$logTime <- log(ide3$Time) # add new column
shapiro.test(ide3[ide3$IDE == "PyCharm",]$logTime)
Shapiro-Wilk normality test
data: ide3[ide3$IDE == "PyCharm", ]$logTime
W = 0.96579, p-value = 0.6648m <- aov(logTime ~ IDE, data=ide3) # fit model
shapiro.test(residuals(m)) # test residuals
Shapiro-Wilk normality test
data: residuals(m)
W = 0.96563, p-value = 0.08893par(pin=c(2.75,1.25),cex=0.5)
qqnorm(residuals(m)); qqline(residuals(m)) # plot residuals
#. test homoscedasticity
leveneTest(logTime ~ IDE, data=ide3, center=median) # Brown-Forsythe testLevene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 1.7797 0.1779
57 13.3.8 Can we transform data so it fits assumptions? (One-way ANOVA, suitable now to logTime)
m <- aov(logTime ~ IDE, data=ide3) # fit model
anova(m) # report anovaAnalysis of Variance Table
Response: logTime
Df Sum Sq Mean Sq F value Pr(>F)
IDE 2 2.3064 1.1532 8.796 0.0004685 ***
Residuals 57 7.4729 0.1311
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#. post hoc independent-samples t-tests
pacman::p_load(multcomp)
summary(glht(m, mcp(IDE="Tukey")), test=adjusted(type="holm")) # Tukey means compare all pairs
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: aov(formula = logTime ~ IDE, data = ide3)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
PyCharm - Eclipse == 0 -0.4380 0.1145 -3.826 0.000978 ***
VStudio - Eclipse == 0 -0.3895 0.1145 -3.402 0.002458 **
VStudio - PyCharm == 0 0.0485 0.1145 0.424 0.673438
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- holm method)#. note: equivalent to this using lsm instead of mcp
pacman::p_load(emmeans)
summary(glht(m, lsm(pairwise ~ IDE)), test=adjusted(type="holm"))
Simultaneous Tests for General Linear Hypotheses
Fit: aov(formula = logTime ~ IDE, data = ide3)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
Eclipse - PyCharm == 0 0.4380 0.1145 3.826 0.000978 ***
Eclipse - VStudio == 0 0.3895 0.1145 3.402 0.002458 **
PyCharm - VStudio == 0 -0.0485 0.1145 -0.424 0.673438
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- holm method)13.3.9 What if we can’t transform data to fit ANOVA assumptions? (Nonparametric equivalent of one-way ANOVA)
#. Kruskal-Wallis test
kruskal_test(Time ~ IDE, data=ide3, distribution="asymptotic") # can't do exact with 3 levels
Asymptotic Kruskal-Wallis Test
data: Time by IDE (Eclipse, PyCharm, VStudio)
chi-squared = 12.17, df = 2, p-value = 0.002277kruskal_test(logTime ~ IDE, data=ide3, distribution="asymptotic") # note: same result
Asymptotic Kruskal-Wallis Test
data: logTime by IDE (Eclipse, PyCharm, VStudio)
chi-squared = 12.17, df = 2, p-value = 0.002277#. for reporting Kruskal-Wallis as chi-square, we can get N with nrow(ide3)
#. manual post hoc Mann-Whitney U pairwise comparisons
#. note: wilcox_test we used above doesn't take two data vectors, so use wilcox.test
vs.ec <- wilcox.test(ide3[ide3$IDE == "VStudio",]$Time,
ide3[ide3$IDE == "Eclipse",]$Time, exact=FALSE)
vs.py <- wilcox.test(ide3[ide3$IDE == "VStudio",]$Time,
ide3[ide3$IDE == "PyCharm",]$Time, exact=FALSE)
ec.py <- wilcox.test(ide3[ide3$IDE == "Eclipse",]$Time,
ide3[ide3$IDE == "PyCharm",]$Time, exact=FALSE)
p.adjust(c(vs.ec$p.value, vs.py$p.value, ec.py$p.value), method="holm")[1] 0.007681846 0.588488864 0.007681846#. alternative approach is using PMCMRplus for nonparam pairwise comparisons
pacman::p_load(PMCMRplus)
kwAllPairsConoverTest(Time ~ IDE, data=ide3, p.adjust.method="holm")Warning in kwAllPairsConoverTest.default(c(341, 291, 283, 155, 271, 270, : Ties
are present. Quantiles were corrected for ties.
Pairwise comparisons using Conover's all-pairs testdata: Time by IDE Eclipse PyCharm
PyCharm 0.0025 -
VStudio 0.0062 0.6620
P value adjustment method: holmThe above test was reported by W. J. Conover and R. L. Iman (1979), On multiple-comparisons procedures, Tech. Rep. LA-7677-MS, Los Alamos Scientific Laboratory.
13.3.10 Another example of tasks using two tools (More on oneway ANOVA)
The designtime data records task times in minutes to complete the same project in Illustrator or InDesign.
Read the designtime data into R. Determine how many subjects participated.
dt <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/designtime.csv"))
#. convert Subject to a factor
dt$Subject<-as.factor(dt$Subject)
dt$Tool<-as.factor(dt$Tool)
summary(dt) Subject Tool Time
1 : 1 Illustrator:30 Min. : 98.19
2 : 1 InDesign :30 1st Qu.:149.34
3 : 1 Median :205.54
4 : 1 Mean :275.41
5 : 1 3rd Qu.:361.99
6 : 1 Max. :926.15
(Other):54 length(dt$Subject)[1] 60tail(dt)# A tibble: 6 × 3
Subject Tool Time
<fct> <fct> <dbl>
1 55 Illustrator 218.
2 56 InDesign 180.
3 57 Illustrator 170.
4 58 InDesign 186.
5 59 Illustrator 241.
6 60 InDesign 159.We see from the summary that there are sixty observations. We can see the same by checking the length() of the Subject (or any other) variable in the data.
Create a boxplot of the task time for each tool and comment on the medians and variances.
ggplot(dt,aes(Tool,Time,fill=Tool)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=8)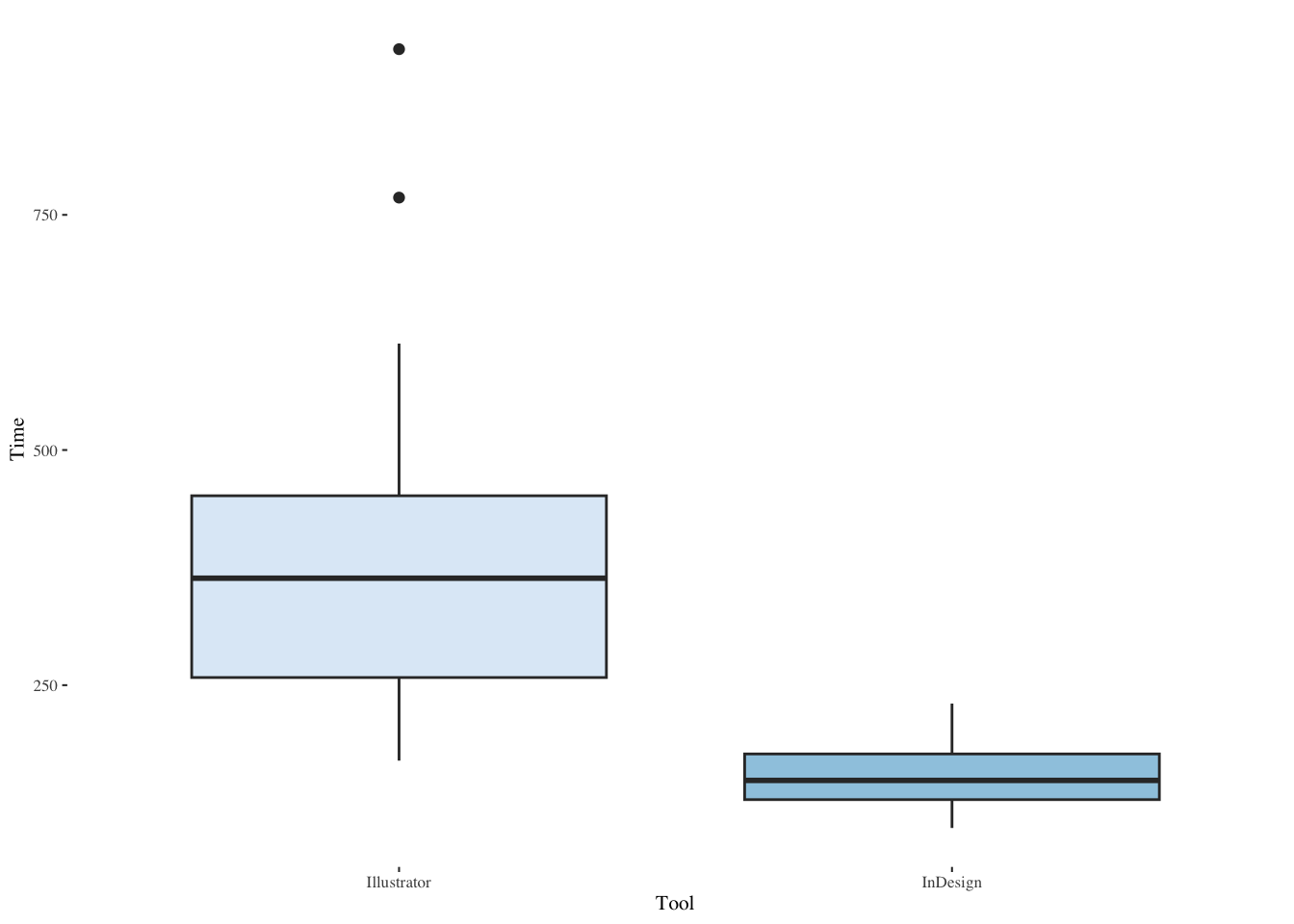
Both the median and the variance is much larger for Illustrator than for InDesign.
Conduct a Shapiro-Wilk test for normality for each tool and comment.
shapiro.test(dt[dt$Tool=="Illustrator",]$Time)
Shapiro-Wilk normality test
data: dt[dt$Tool == "Illustrator", ]$Time
W = 0.90521, p-value = 0.01129shapiro.test(dt[dt$Tool=="InDesign",]$Time)
Shapiro-Wilk normality test
data: dt[dt$Tool == "InDesign", ]$Time
W = 0.95675, p-value = 0.2553In the case of InDesign, we fail to reject the null hypothesis that the data are drawn from a normal distribution. In the case of Illustrator, we reject the null hypothesis at the five percent level but not at the one percent level (just barely).
Conduct a Shapiro-Wilk test for normality on the residuals and comment.
m<-aov(Time~Tool,data=dt)
shapiro.test(residuals(m))
Shapiro-Wilk normality test
data: residuals(m)
W = 0.85077, p-value = 3.211e-06We reject the null hypothesis that the residuals are normally distributed.
Conduct a Brown-Forsythe test of homoscedasticity.
leveneTest(Time~Tool,data=dt,center=median)Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 20.082 3.545e-05 ***
58
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1We reject the null hypothesis that the two samples are drawn from populations with equal variance.
Fit a lognormal distribution to the Time response for each Tool. Conduct a Kolmogorov-Smirnov goodness-of-fit test and comment.
fit<-fitdistr(dt[dt$Tool=="Illustrator",]$Time,
"lognormal")$estimate
tst<-ks.test(dt[dt$Tool=="Illustrator",]$Time,
"plnorm",meanlog=fit[1],sdlog=fit[2],exact=TRUE)
tst
Exact one-sample Kolmogorov-Smirnov test
data: dt[dt$Tool == "Illustrator", ]$Time
D = 0.093358, p-value = 0.9344
alternative hypothesis: two-sidedfit<-fitdistr(dt[dt$Tool=="InDesign",]$Time,
"lognormal")$estimate
tst<-ks.test(dt[dt$Tool=="InDesign",]$Time,
"plnorm",meanlog=fit[1],sdlog=fit[2],exact=TRUE)
tst
Exact one-sample Kolmogorov-Smirnov test
data: dt[dt$Tool == "InDesign", ]$Time
D = 0.10005, p-value = 0.8958
alternative hypothesis: two-sidedWe fail to reject the null hypothesis that the Illustrator sample is drawn from a lognormal distribution. We fail to reject the null hypothesis that the InDesign sample is drawn from a lognormal distribution.
Create a log-transformed Time response column. Compute the mean for each tool and comment.
dt$logTime<-log(dt$Time)
mean(dt$logTime[dt$Tool=="Illustrator"])[1] 5.894288mean(dt$logTime[dt$Tool=="InDesign"])[1] 5.03047dt |>
group_by(Tool) |>
summarize(mean=mean(logTime),sd=sd(logTime))# A tibble: 2 × 3
Tool mean sd
<fct> <dbl> <dbl>
1 Illustrator 5.89 0.411
2 InDesign 5.03 0.211The mean for Illustrator appears to be larger than the mean for InDesign.
Conduct an independent-samples \(t\)-test on the log-transformed Time response, using the Welch version for unequal variances and comment.
t.test(logTime~Tool,data=dt,var.equal=FALSE)
Welch Two Sample t-test
data: logTime by Tool
t = 10.23, df = 43.293, p-value = 3.98e-13
alternative hypothesis: true difference in means between group Illustrator and group InDesign is not equal to 0
95 percent confidence interval:
0.6935646 1.0340718
sample estimates:
mean in group Illustrator mean in group InDesign
5.894288 5.030470 We reject the null hypothesis that the true difference in means is equal to 0.
Conduct an exact nonparametric Mann-Whitney \(U\) test on the Time response and comment.
wilcox_test(Time~Tool,data=dt,distribution="exact")
Exact Wilcoxon-Mann-Whitney Test
data: Time by Tool (Illustrator, InDesign)
Z = 6.3425, p-value = 5.929e-14
alternative hypothesis: true mu is not equal to 0We reject the null hypothesis that the samples were drawn from populations with the same distribution.
13.3.11 Differences in writing speed among three tools (Three levels of a factor in ANOVA)
We’ll examine three levels of a factor, which is an alphabet system used for writing. The three levels are named for the text entry systems, EdgeWrite, Graffiti, and Unistrokes.
alpha <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/alphabets.csv"))
alpha$Subject<-as.factor(alpha$Subject)
alpha$Alphabet<-as.factor(alpha$Alphabet)
summary(alpha) Subject Alphabet WPM
1 : 1 EdgeWrite :20 Min. : 3.960
2 : 1 Graffiti :20 1st Qu.: 9.738
3 : 1 Unistrokes:20 Median :13.795
4 : 1 Mean :14.517
5 : 1 3rd Qu.:18.348
6 : 1 Max. :28.350
(Other):54 Plot the three text entry systems. ::: {.cell}
ggplot(alpha,aes(Alphabet,WPM,fill=Alphabet)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=7)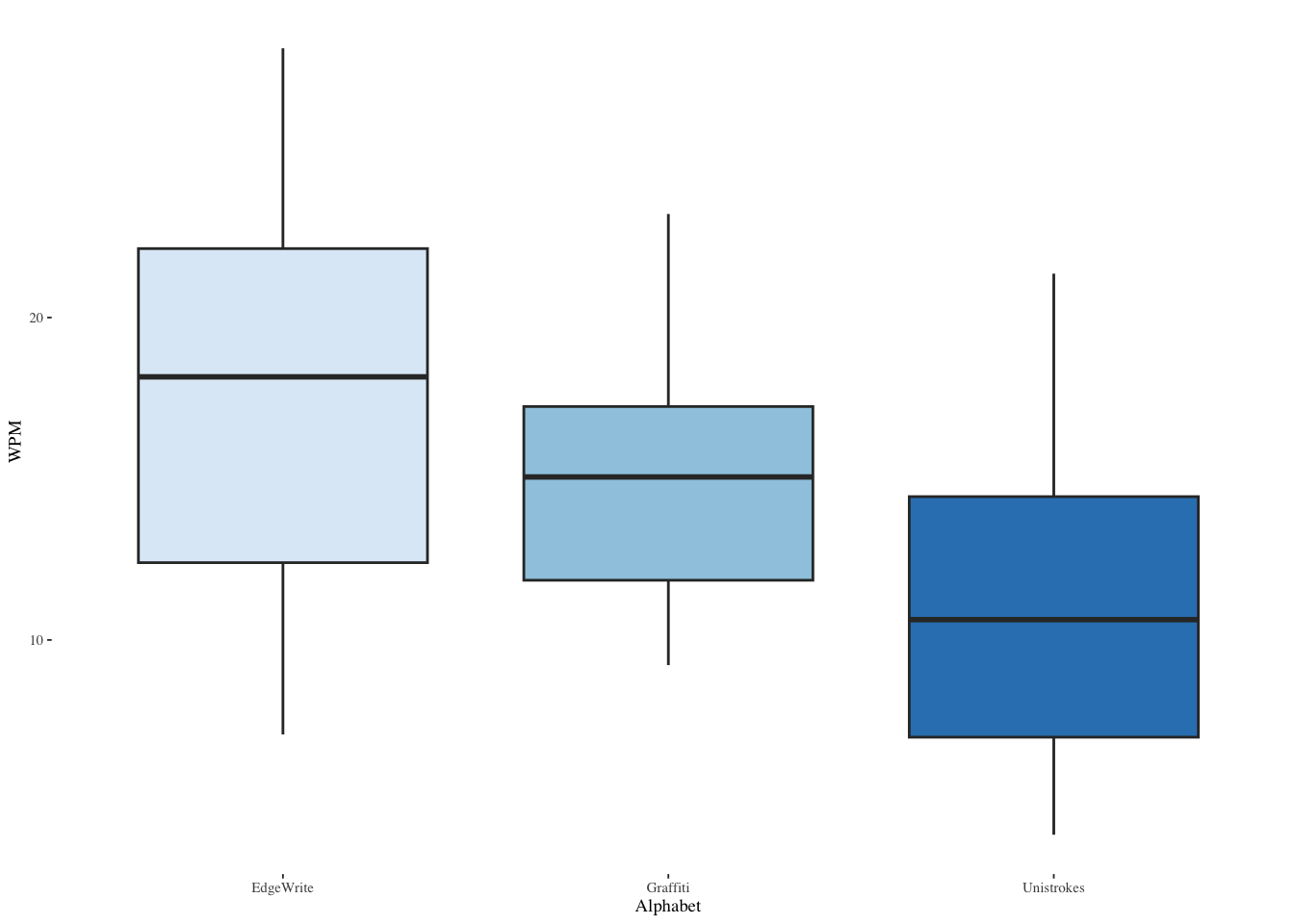
:::
Identify the average words per minute written with EdgeWrite.
mean(alpha[alpha$Alphabet=="EdgeWrite",]$WPM)[1] 17.14Conduct a Shapiro-Wilk test for normality on each method.
shapiro.test(alpha$WPM[alpha$Alphabet=="EdgeWrite"])
Shapiro-Wilk normality test
data: alpha$WPM[alpha$Alphabet == "EdgeWrite"]
W = 0.95958, p-value = 0.5355shapiro.test(alpha$WPM[alpha$Alphabet=="Graffiti"])
Shapiro-Wilk normality test
data: alpha$WPM[alpha$Alphabet == "Graffiti"]
W = 0.94311, p-value = 0.2743shapiro.test(alpha$WPM[alpha$Alphabet=="Unistrokes"])
Shapiro-Wilk normality test
data: alpha$WPM[alpha$Alphabet == "Unistrokes"]
W = 0.94042, p-value = 0.2442Conduct a Shapiro-Wilk test for normality on the residuals of an ANOVA model stipulating that Alphabet affects WPM.
m<-aov(WPM~Alphabet,data=alpha)
shapiro.test(residuals(m))
Shapiro-Wilk normality test
data: residuals(m)
W = 0.97762, p-value = 0.3363Test for homoscedasticity.
leveneTest(alpha$WPM~alpha$Alphabet,center="median")Levene's Test for Homogeneity of Variance (center = "median")
Df F value Pr(>F)
group 2 1.6219 0.2065
57 Now test all three. The mcp function tests multiple means. The keyword Tukey means to do all the possible pairwise comparisons of Alphabet, i.e., Graffiti and EdgeWrite, Graffiti and Unistrokes, and EdgeWrite and Unistrokes. m is the oneway ANOVA model we created above.
summary(multcomp::glht(m,multcomp::mcp(Alphabet="Tukey")),test=adjusted(type="holm"))
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: aov(formula = WPM ~ Alphabet, data = alpha)
Linear Hypotheses:
Estimate Std. Error t value Pr(>|t|)
Graffiti - EdgeWrite == 0 -2.101 1.693 -1.241 0.21982
Unistrokes - EdgeWrite == 0 -5.769 1.693 -3.407 0.00363 **
Unistrokes - Graffiti == 0 -3.668 1.693 -2.166 0.06894 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- holm method)Conduct a nonparametric oneway ANOVA using the Kruskal-Wallis test to see if the samples have the same distribution. The null hypothesis is that the samples come from the same distribution.
kruskal_test(alpha$WPM~alpha$Alphabet,distribution="asymptotic")
Asymptotic Kruskal-Wallis Test
data: alpha$WPM by
alpha$Alphabet (EdgeWrite, Graffiti, Unistrokes)
chi-squared = 9.7019, df = 2, p-value = 0.007821Conduct manual post hoc Mann-Whitney pairwise comparisons and adjust the \(p\)-values to take into account the possibility of false discovery.
ewgf<-wilcox.test(alpha$WPM[alpha$Alphabet=="EdgeWrite"],alpha$WPM[alpha$Alphabet=="Graffiti"],paired=FALSE,exact=FALSE)
ewun<-wilcox.test(alpha$WPM[alpha$Alphabet=="EdgeWrite"],alpha$WPM[alpha$Alphabet=="Unistrokes"],paired=FALSE,exact=FALSE)
gfun<-wilcox.test(alpha$WPM[alpha$Alphabet=="Graffiti"],alpha$WPM[alpha$Alphabet=="Unistrokes"],paired=FALSE,exact=FALSE)
p.adjust(c(ewgf$p.value,ewun$p.value,gfun$p.value),method="holm")[1] 0.20358147 0.01810677 0.0414691913.4 Same person using two different tools (Paired samples \(t\)-test)
Is it better to search or scroll for contacts in a smartphone contacts manager? Which takes more time? Which takes more effort? Which is more error-prone? Start by reading in data, converting to factors, and summarizing.
srchscrl <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/srchscrl.csv"))
srchscrl$Subject <- factor(srchscrl$Subject)
srchscrl$Order <- factor(srchscrl$Order)
srchscrl$Technique <- factor(srchscrl$Technique)
#. srchscrl$Errors <- factor(srchscrl$Errors,ordered=TRUE,levels=c(0,1,2,3,4))
summary(srchscrl) Subject Technique Order Time Errors Effort
1 : 2 Scroll:20 1:20 Min. : 49.0 Min. :0.00 Min. :1
2 : 2 Search:20 2:20 1st Qu.: 94.5 1st Qu.:0.75 1st Qu.:3
3 : 2 Median :112.5 Median :1.50 Median :4
4 : 2 Mean :117.0 Mean :1.60 Mean :4
5 : 2 3rd Qu.:148.2 3rd Qu.:2.25 3rd Qu.:5
6 : 2 Max. :192.0 Max. :4.00 Max. :7
(Other):28 pacman::p_load(xtable)
options(xtable.comment=FALSE)
options(xtable.booktabs=TRUE)
xtable(head(srchscrl),caption="First rows of data")View descriptive statistics by Technique. There are several ways to do this. The following uses the plyr package. ::: {.cell}
plyr::ddply(srchscrl, ~ Technique,
function(data) summary(data$Time)) Technique Min. 1st Qu. Median Mean 3rd Qu. Max.
1 Scroll 49 123.50 148.5 137.2 161 192
2 Search 50 86.75 99.5 96.8 106 147plyr::ddply(srchscrl, ~ Technique,
summarise, Time.mean=mean(Time), Time.sd=sd(Time)) Technique Time.mean Time.sd
1 Scroll 137.2 35.80885
2 Search 96.8 23.23020:::
Another approach is to use the dplyr package. Be aware that it conflicts with plyr so you should try to avoid using both. If you must use both, as I did above, it may make the most sense to call particular functions from the plyr package rather than load the package. This is what I did with plyr::ddply() above.
srchscrl |>
group_by(Technique) |>
summarize(mean=mean(Time),sd=sd(Time))# A tibble: 2 × 3
Technique mean sd
<fct> <dbl> <dbl>
1 Scroll 137. 35.8
2 Search 96.8 23.2You can explore the Time response by making histograms or boxplots. One approach is to use the ggplot2 package and put the histograms together in one frame. The ggplot2 package allows for a remarkable variety of options.
ggplot(srchscrl,aes(Time,fill=Technique)) +
geom_histogram(bins=30,alpha=0.9,position=position_dodge()) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=8)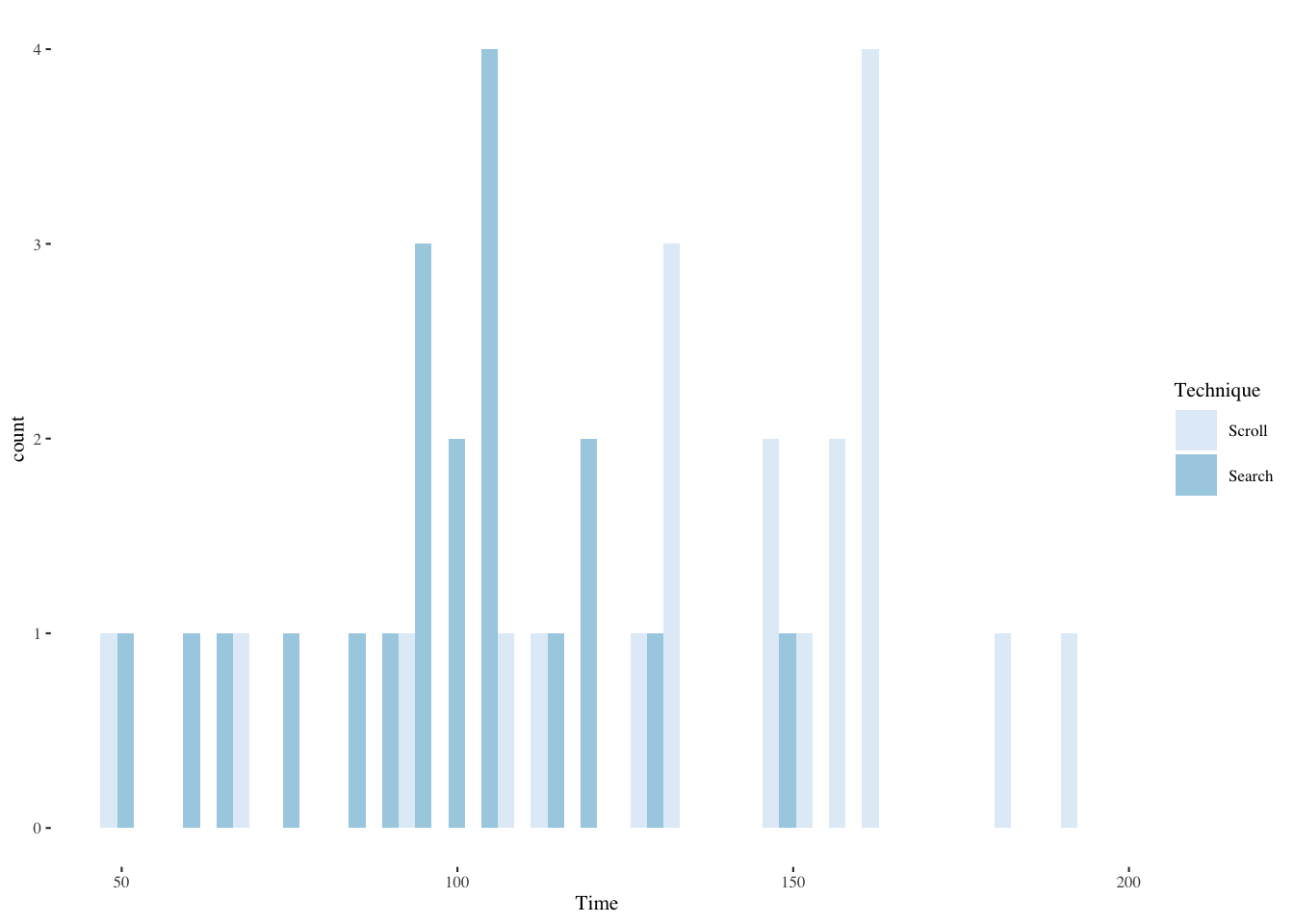
We can use the same package for boxplots. Boxplots show the median as a bold line in the middle of the box. The box itself ranges from the first quartile (starting at the 25th percentile) to the third quartile (terminating at the 75th percentile). The whiskers run from the minimum to the maximum, where these are defined as the 25th percentile minus 1.5 times the interquartile range and the 75th percentile plus 1.5 times the interquartile range. The interquartile range is the width of the box. Dots outside the whiskers show outliers.
ggplot(srchscrl,aes(Technique,Time,fill=Technique)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=8)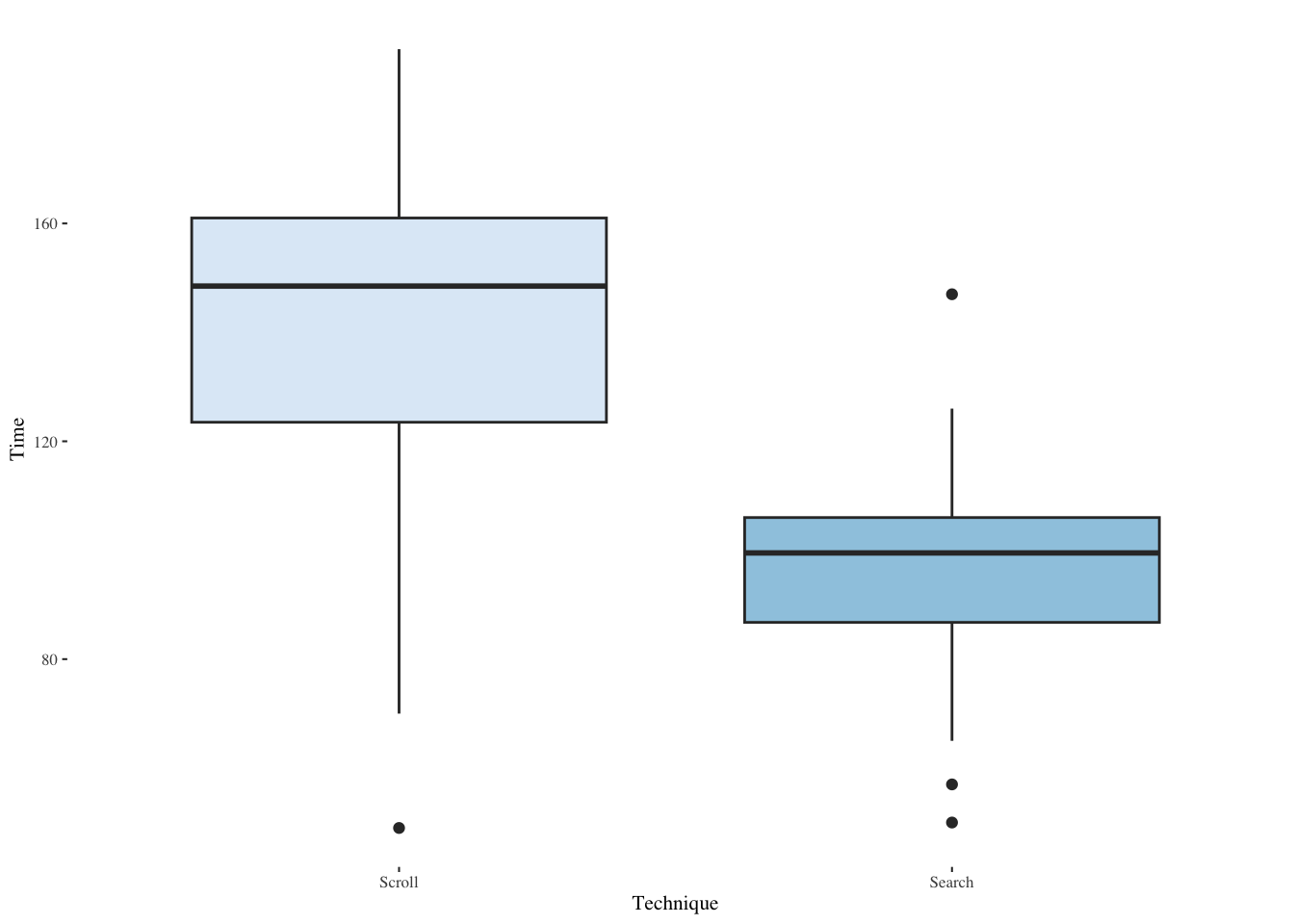
We would rather use parametric statistics if ANOVA assumptions are met. Recall that we can test for normality, normality of residuals, and homoscedasticity. In the case of a within-subjects experiment, we can also test for order effects which is one way to test the independence assumption. First test whether these times seem to be drawn from a normal distribution.
shapiro.test(srchscrl[srchscrl$Technique == "Search",]$Time)
Shapiro-Wilk normality test
data: srchscrl[srchscrl$Technique == "Search", ]$Time
W = 0.96858, p-value = 0.7247shapiro.test(srchscrl[srchscrl$Technique == "Scroll",]$Time)
Shapiro-Wilk normality test
data: srchscrl[srchscrl$Technique == "Scroll", ]$Time
W = 0.91836, p-value = 0.09213In both cases we fail to reject the null hypothesis, which is that the Time data are drawn from a normal distribution. Note that we fail to reject at \(\alpha=0.05\) but that in the case of the Scroll technique we would reject at \(\alpha=0.1\).
Fit a model for testing residuals—the Error function is used to indicate within-subject effects, i.e., each Subject was exposed to all levels of Technique. generally, Error(S/(ABC)) means each S was exposed to every level of A, B, C and S is a column encoding subject ids.
m <- aov(Time ~ Technique + Error(Subject/Technique),
data=srchscrl)The above-specified model has residuals—departures of the observed data from the data that would be expected if the model were accurate.
Now we can test the residuals of this model for normality and also examine a QQ plot for normality. The QQ plot shows the theoretical line to which the residuals should adhere if they are normally distributed. Deviations from that line are indications of non-normality. First test by Subject.
shapiro.test(residuals(m$Subject))
Shapiro-Wilk normality test
data: residuals(m$Subject)
W = 0.9603, p-value = 0.5783qqnorm(residuals(m$Subject))
qqline(residuals(m$Subject))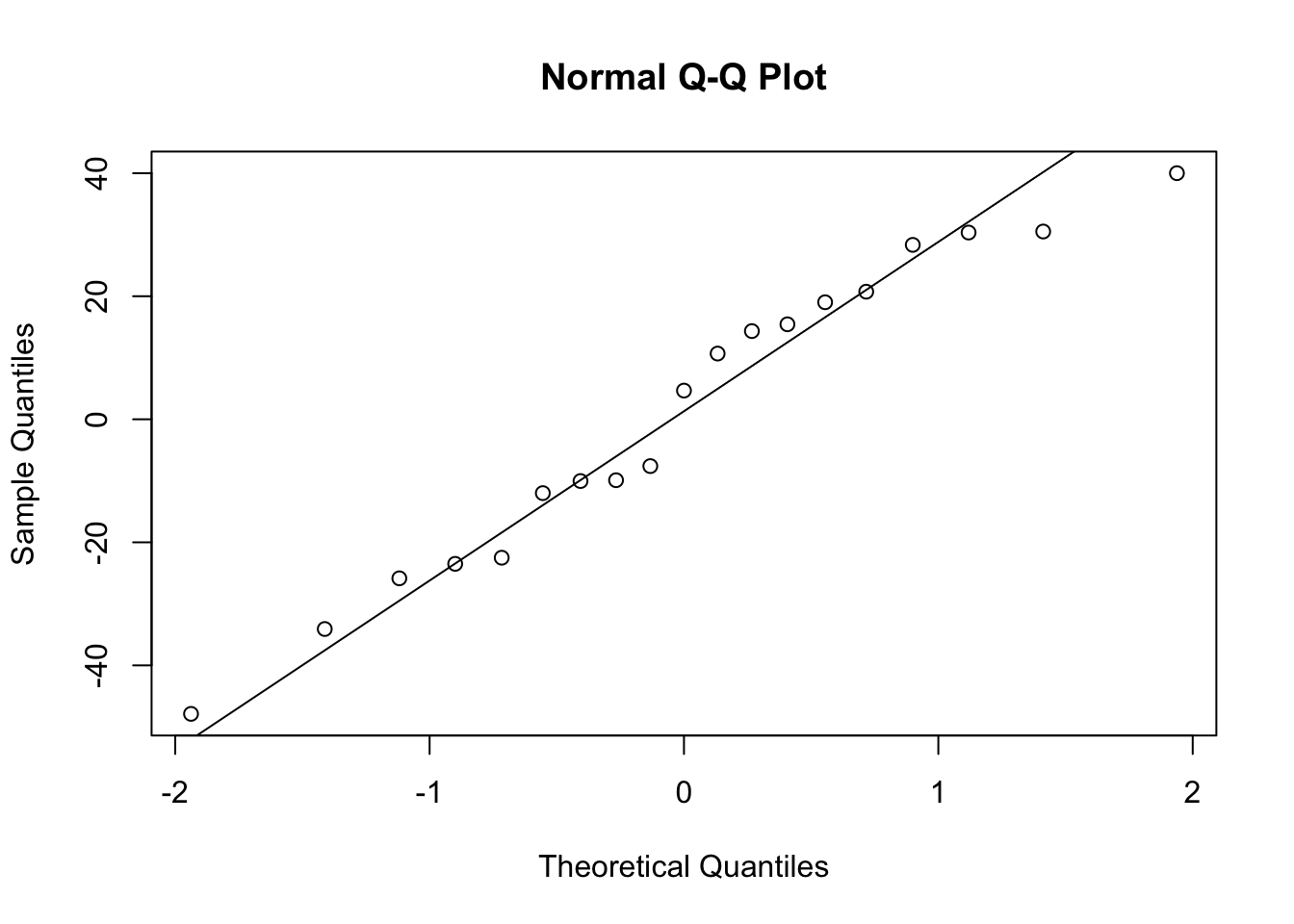
We fail to reject the null hypothesis of normality and the QQ plot looks normal. So far, so good.
Next test by Subject:Technique.
shapiro.test(residuals(m$'Subject:Technique'))
Shapiro-Wilk normality test
data: residuals(m$"Subject:Technique")
W = 0.97303, p-value = 0.8172qqnorm(residuals(m$'Subject:Technique'))
qqline(residuals(m$'Subject:Technique'))
We fail to reject the null hypothesis of normality and the QQ plot looks normal. We’re getting there.
We’re still checking the ANOVA assumptions. Next thing to test is homoscedasticity, the assumption of equal variance. For this we use the Brown-Forsythe test, a variant of Levene’s test that uses the median instead of the mean, providing greater robustness against non-normal data.
leveneTest(Time ~ Technique, data=srchscrl, center=median)Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 2.0088 0.1645
38 This experiment used counterbalancing to ward off the possibility of an order effect. An order effect results from learning or fatigue or some other factor based on the order in which the tests were run. We would like to not have that happen and one solution is to have half the subjects do task A first and half the subjects do task B first. This is the simplest form of counterbalancing. It becomes more problematic if there are more than two tasks.
For a paired-samples \(t\)-test we must use a wide-format table; most R functions do not require a wide-format table, but the dcast() function offers a quick way to translate long-format into wide-format when we need it.
A wide-format table has one subject in every row. A long-format table has one observation in every row. Most R functions use long-format tables.
pacman::p_load(reshape2)
srchscrl.wide.order <- dcast(srchscrl, Subject ~ Order,
value.var="Time")xtable(head(srchscrl.wide.order),
caption="First rows of wide order")Now conduct a \(t\)-test to see if order has an effect. ::: {.cell}
t.test(srchscrl.wide.order$"1", srchscrl.wide.order$"2",
paired=TRUE, var.equal=TRUE)
Paired t-test
data: srchscrl.wide.order$"1" and srchscrl.wide.order$"2"
t = -1.3304, df = 19, p-value = 0.1991
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-47.34704 10.54704
sample estimates:
mean difference
-18.4 :::
We fail to reject the null hypothesis that the responses do not differ according to order. To phrase this in a more readable (!) way, we have evidence that the order does not matter.
13.4.1 Running the paired \(t\)-test
It now makes sense to use a paired \(t\)-test since the ANOVA assumptions have been satisfied. This is a parametric test of Time where we pair subjects by technique. Again, we need the wide-format table to conduct a paired test. The wide-format table has one row for each subject rather than one row for each observation.
srchscrl.wide.tech = dcast(srchscrl, Subject ~ Technique,
value.var="Time")xtable(head(srchscrl.wide.tech),
caption="First rows of wide technique")t.test(srchscrl.wide.tech$Search, srchscrl.wide.tech$Scroll,
paired=TRUE, var.equal=TRUE)
Paired t-test
data: srchscrl.wide.tech$Search and srchscrl.wide.tech$Scroll
t = -3.6399, df = 19, p-value = 0.001743
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-63.63083 -17.16917
sample estimates:
mean difference
-40.4 This supports the intuition we developed doing the histogram and boxplots only now we have a valid statistical test to support this intuition.
Suppose we did not satisfy the ANOVA assumptions. Then we would conduct the nonparametric equivalent of paired-samples t-test.
13.4.2 Exploring a Poisson-distributed factor
Explore the Errors response; error counts are often Poisson-distributed.
plyr::ddply(srchscrl, ~ Technique, function(data)
summary(data$Errors)) Technique Min. 1st Qu. Median Mean 3rd Qu. Max.
1 Scroll 0 0 0.5 0.7 1 2
2 Search 1 2 2.5 2.5 3 4plyr::ddply(srchscrl, ~ Technique, summarise,
Errors.mean=mean(Errors), Errors.sd=sd(Errors)) Technique Errors.mean Errors.sd
1 Scroll 0.7 0.8013147
2 Search 2.5 1.0513150ggplot(srchscrl,aes(Errors,fill=Technique)) +
geom_histogram(bins=20,alpha=0.9,position=position_dodge()) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=8)
ggplot(srchscrl,aes(Technique,Errors,fill=Technique)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=8)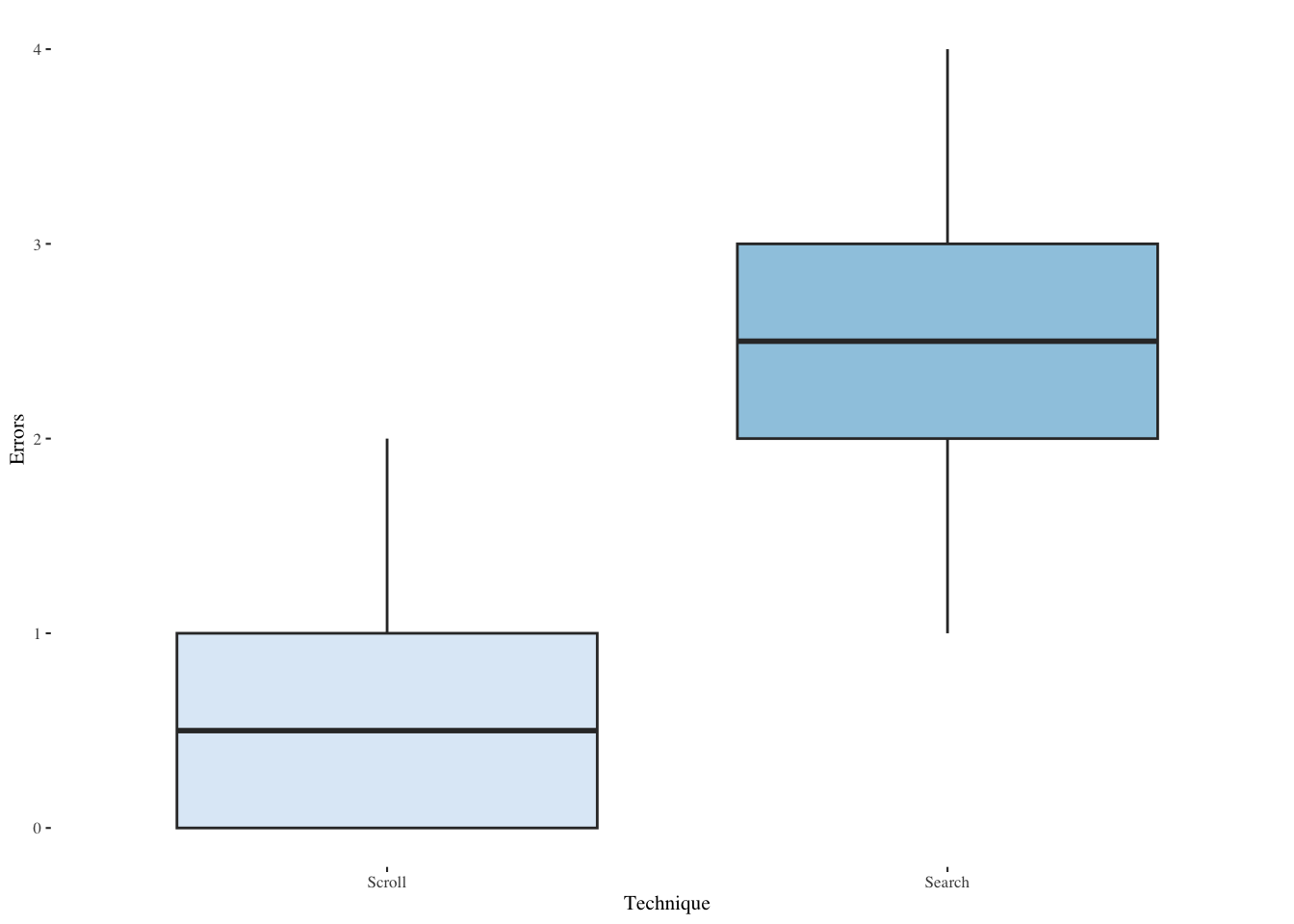
Try to fit a Poisson distribution for count data. Note that ks.test() only works for continuous distributions, but Poisson distributions are discrete, so use fitdist, not fitdistr, and test with gofstat.
pacman::p_load(fitdistrplus)
fit = fitdist(srchscrl[srchscrl$Technique == "Search",]$Errors,
"pois", discrete=TRUE)
gofstat(fit) # goodness-of-fit testChi-squared statistic: 1.522231
Degree of freedom of the Chi-squared distribution: 2
Chi-squared p-value: 0.4671449
the p-value may be wrong with some theoretical counts < 5
Chi-squared table:
obscounts theocounts
<= 1 4.000000 5.745950
<= 2 6.000000 5.130312
<= 3 6.000000 4.275260
> 3 4.000000 4.848477
Goodness-of-fit criteria
1-mle-pois
Akaike's Information Criterion 65.61424
Bayesian Information Criterion 66.60997fit = fitdist(srchscrl[srchscrl$Technique == "Scroll",]$Errors,
"pois", discrete=TRUE)
gofstat(fit) # goodness-of-fit testChi-squared statistic: 0.3816087
Degree of freedom of the Chi-squared distribution: 1
Chi-squared p-value: 0.5367435
the p-value may be wrong with some theoretical counts < 5
Chi-squared table:
obscounts theocounts
<= 0 10.000000 9.931706
<= 1 6.000000 6.952194
> 1 4.000000 3.116100
Goodness-of-fit criteria
1-mle-pois
Akaike's Information Criterion 45.53208
Bayesian Information Criterion 46.52781Conduct a Wilcoxon signed-rank test on Errors. ::: {.cell}
wilcoxsign_test(Errors ~ Technique | Subject,
data=srchscrl, distribution="exact")
Exact Wilcoxon-Pratt Signed-Rank Test
data: y by x (pos, neg)
stratified by block
Z = -3.6701, p-value = 6.104e-05
alternative hypothesis: true mu is not equal to 0:::
Note: the term afer the “|” indicates the within-subjects blocking term for matched pairs.
13.4.3 Examining a Likert scale response item
Now also examine Effort, the ordinal Likert scale response (1-7).
plyr::ddply(srchscrl, ~ Technique, function(data)
summary(data$Effort)) Technique Min. 1st Qu. Median Mean 3rd Qu. Max.
1 Scroll 1 3 4 4.4 6.00 7
2 Search 1 3 4 3.6 4.25 5plyr::ddply(srchscrl, ~ Technique, summarise,
Effort.mean=mean(Effort), Effort.sd=sd(Effort)) Technique Effort.mean Effort.sd
1 Scroll 4.4 1.698296
2 Search 3.6 1.187656ggplot(srchscrl,aes(Effort,fill=Technique)) +
geom_histogram(bins=20,alpha=0.9,position=position_dodge()) +
scale_fill_brewer(palette="Blues") +
theme_tufte(base_size=8)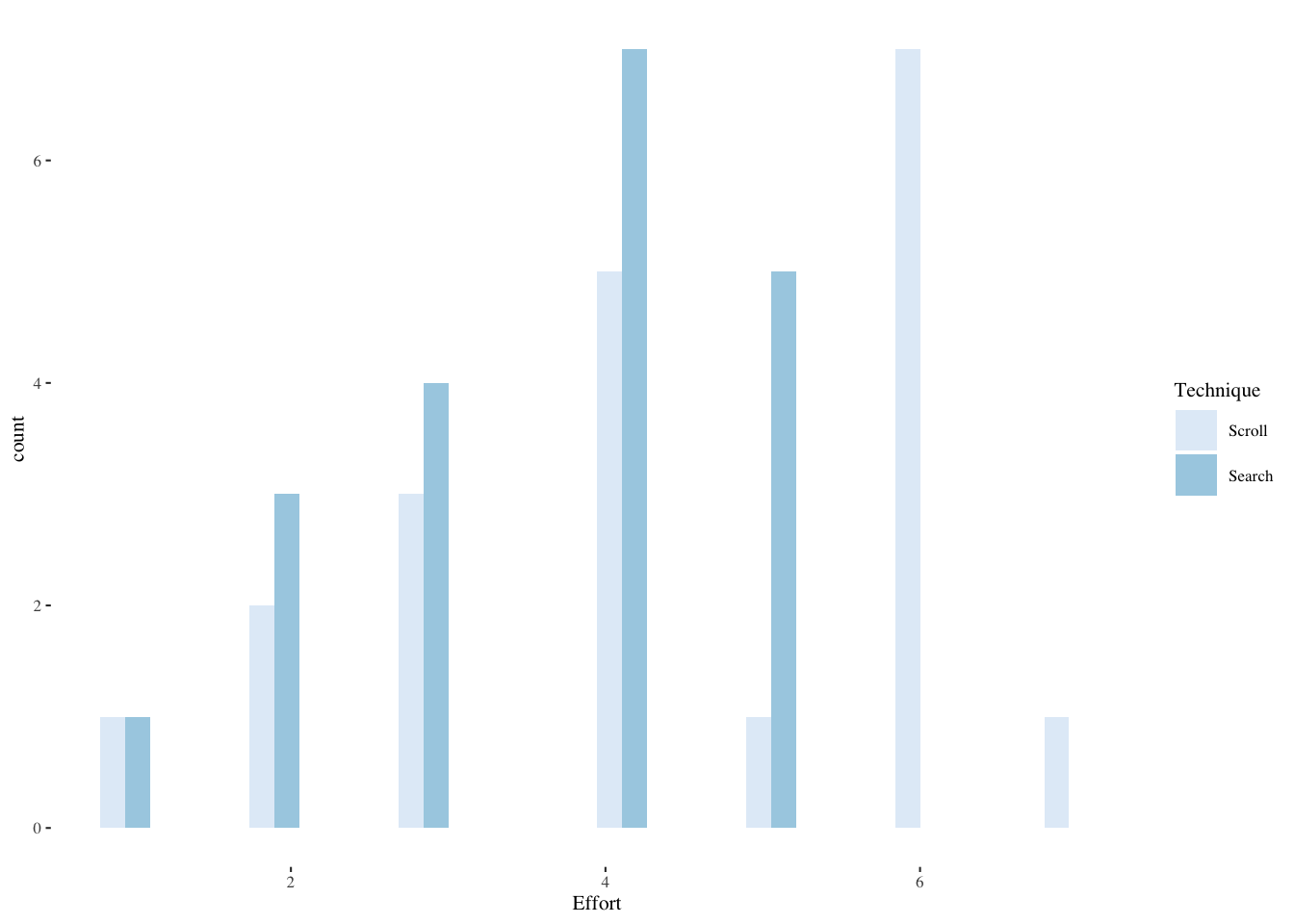
ggplot(srchscrl,aes(Technique,Effort,fill=Technique)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Set3") +
geom_dotplot(show.legend=FALSE,binaxis='y',stackdir='center',dotsize=1) +
theme_tufte(base_size=8)Bin width defaults to 1/30 of the range of the data. Pick better value with
`binwidth`.
Our response is ordinal within-subjects, so use nonparametric Wilcoxon signed-rank.
wilcoxsign_test(Effort ~ Technique | Subject,
data=srchscrl, distribution="exact")
Exact Wilcoxon-Pratt Signed-Rank Test
data: y by x (pos, neg)
stratified by block
Z = 1.746, p-value = 0.08746
alternative hypothesis: true mu is not equal to 013.5 People doing tasks on different phones in different postures (Factorial ANOVA)
The scenario is text entry on smartphone keyboards: iPhone and Galaxy, in different postures: sitting, walking, standing.
The statistics employed include Factorial ANOVA, repeated measures ANOVA, main effects, interaction effects, the Aligned Rank Transform for nonparametric ANOVAs.
This is a \(3 \times 2\) mixed factorial design. It is mixed in the sense that there is a between-subjects factor (Keyboard) and a within-subjects factor (Posture). It is balanced in the sense that there are twelve persons using each Keyboard and they are each examined for all three levels of Posture.
13.5.1 Read and describe the data
mbltxt <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/mbltxt.csv"))
head(mbltxt)# A tibble: 6 × 6
Subject Keyboard Posture Posture_Order WPM Error_Rate
<dbl> <chr> <chr> <dbl> <dbl> <dbl>
1 1 iPhone Sit 1 20.2 0.022
2 1 iPhone Stand 2 23.7 0.03
3 1 iPhone Walk 3 20.8 0.0415
4 2 iPhone Sit 1 20.9 0.022
5 2 iPhone Stand 3 23.3 0.0255
6 2 iPhone Walk 2 19.1 0.0355mbltxt <- within(mbltxt, Subject <- as.factor(Subject))
mbltxt <- within(mbltxt, Keyboard <- as.factor(Keyboard))
mbltxt <- within(mbltxt, Posture <- as.factor(Posture))
mbltxt <- within(mbltxt, Posture_Order <- as.factor(Posture_Order))
summary(mbltxt) Subject Keyboard Posture Posture_Order WPM
1 : 3 Galaxy:36 Sit :24 1:24 Min. : 9.454
2 : 3 iPhone:36 Stand:24 2:24 1st Qu.:19.091
3 : 3 Walk :24 3:24 Median :21.032
4 : 3 Mean :20.213
5 : 3 3rd Qu.:23.476
6 : 3 Max. :25.380
(Other):54
Error_Rate
Min. :0.01500
1st Qu.:0.02200
Median :0.03050
Mean :0.03381
3rd Qu.:0.04000
Max. :0.06950
13.5.2 Explore the WPM (words per minute) data
s <- mbltxt |>
group_by(Keyboard,Posture) |>
summarize(
WPM.median=median(WPM),
WPM.mean=mean(WPM),
WPM.sd=sd(WPM)
)`summarise()` has grouped output by 'Keyboard'. You can override using the
`.groups` argument.s# A tibble: 6 × 5
# Groups: Keyboard [2]
Keyboard Posture WPM.median WPM.mean WPM.sd
<fct> <fct> <dbl> <dbl> <dbl>
1 Galaxy Sit 23.8 23.9 0.465
2 Galaxy Stand 21.2 21.2 0.810
3 Galaxy Walk 12.2 12.1 1.26
4 iPhone Sit 20.9 21.0 0.701
5 iPhone Stand 23.8 23.9 0.834
6 iPhone Walk 19.1 19.2 1.35 13.5.3 Histograms for both factors
ggplot(mbltxt,aes(WPM,fill=Keyboard)) +
geom_histogram(bins=20,alpha=0.9,position="dodge",show.legend=FALSE) +
scale_color_brewer() +
scale_fill_brewer() +
facet_grid(Keyboard~Posture) +
theme_tufte(base_size=8)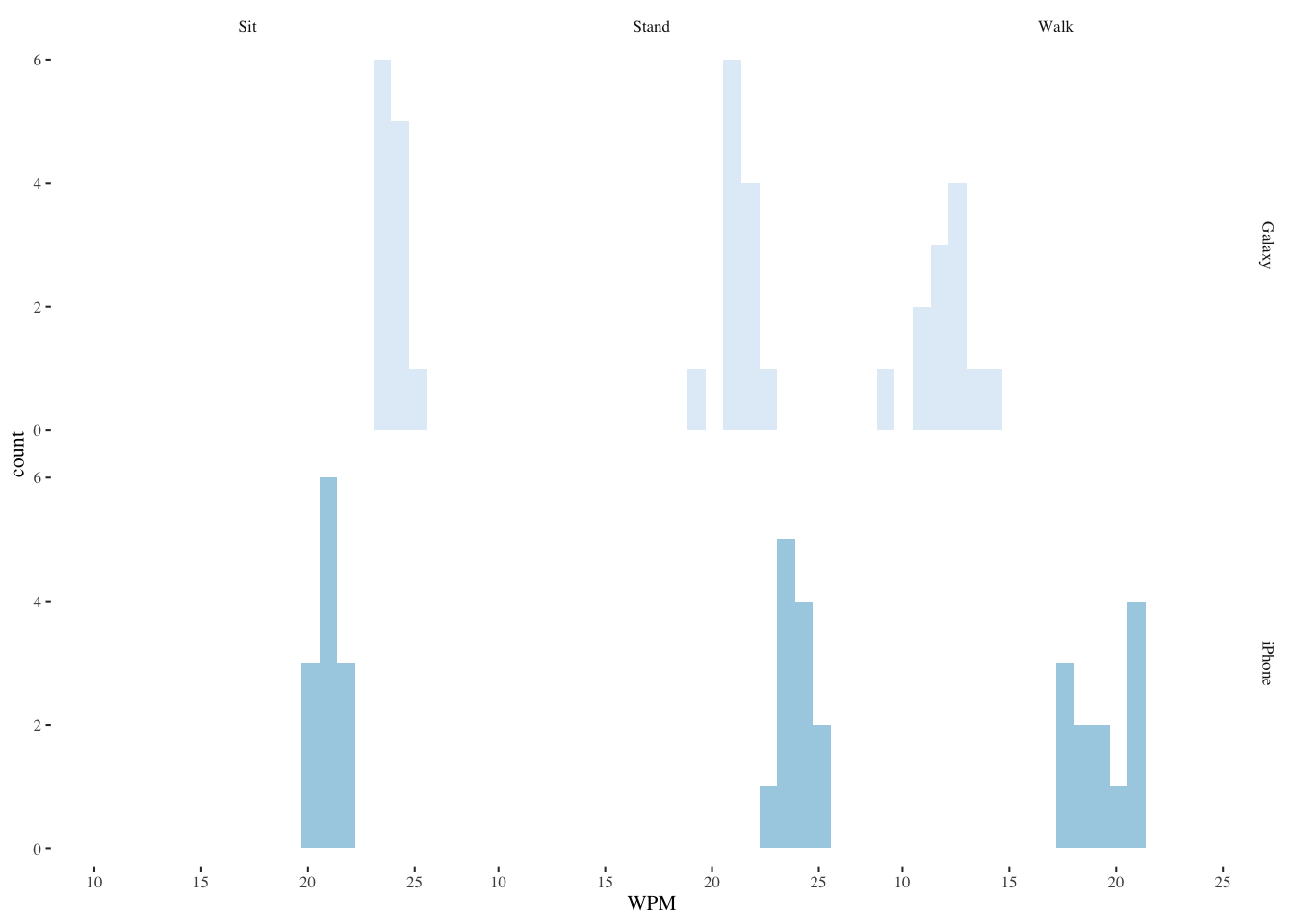
13.5.4 Boxplot of both factors
ggplot(mbltxt,aes(Keyboard,WPM,fill=Keyboard)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Blues") +
facet_wrap(~Posture) +
theme_tufte(base_size=7)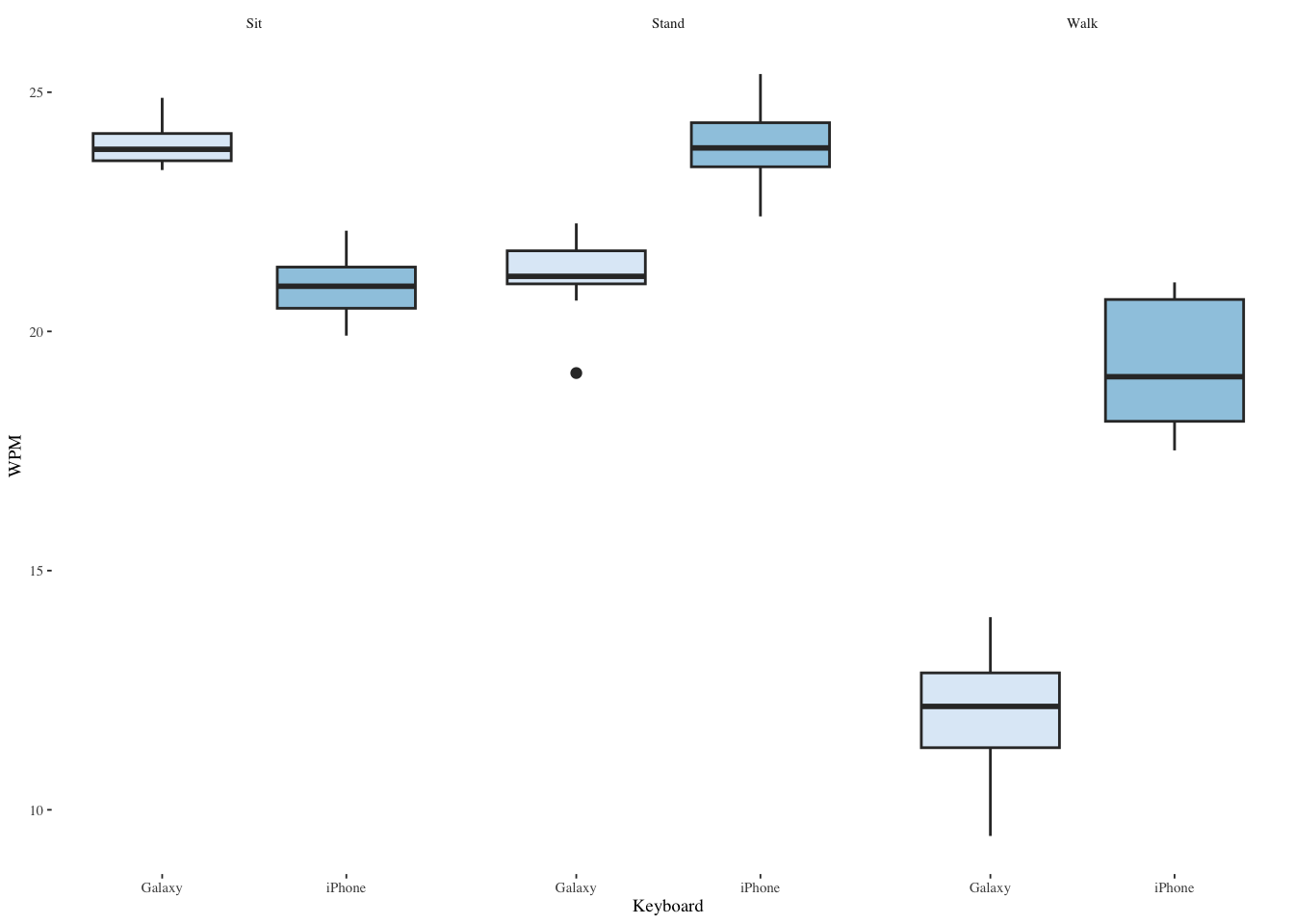
13.5.5 An interaction plot
par(pin=c(2.75,1.25),cex=0.5)
with(mbltxt,
interaction.plot(Posture, Keyboard, WPM,
ylim=c(0, max(mbltxt$WPM))))
13.5.6 Test for a Posture order effect
This is to ensure that counterbalancing worked.
pacman::p_load(ez)
m <- ezANOVA(dv=WPM,
between=Keyboard,
within=Posture_Order,
wid=Subject,
data=mbltxt)
m$Mauchly Effect W p p<.05
3 Posture_Order 0.9912922 0.9122583
4 Keyboard:Posture_Order 0.9912922 0.9122583 Wikipedia tells us that “Sphericity is an important assumption of a repeated-measures ANOVA. It refers to the condition where the variances of the differences between all possible pairs of within-subject conditions (i.e., levels of the independent variable) are equal. The violation of sphericity occurs when it is not the case that the variances of the differences between all combinations of the conditions are equal. If sphericity is violated, then the variance calculations may be distorted, which would result in an \(F\)-ratio that would be inflated.” (from the Wikipedia article on Mauchly’s sphericity test)
Mauchly’s test of sphericity above tells us that there is not a significant departure from sphericity, so we can better rely on the \(F\)-statistic in the following ANOVA, the purpose of which is to detect any order effect that would interfere with our later results.
m$ANOVA Effect DFn DFd F p p<.05 ges
2 Keyboard 1 22 1.244151e+02 1.596641e-10 * 0.0794723123
3 Posture_Order 2 44 5.166254e-02 9.497068e-01 0.0023071128
4 Keyboard:Posture_Order 2 44 2.830819e-03 9.971734e-01 0.0001266932The \(F\)-statistic for Posture_Order is very small, indicating that there is not an order effect. That gives us the confidence to run the ANOVA test we wanted to run all along.
13.6 Differences between people’s performance and within a person’s performance (Two-way mixed factorial ANOVA)
Since a mixed factorial design by definition has both a between-subjects and a within-subjects factor, we don’t need to also mention that this is a repeated measures test.
m <- ezANOVA(dv=WPM,
between=Keyboard,
within=Posture,
wid=Subject,
data=mbltxt)
m$Mauchly Effect W p p<.05
3 Posture 0.6370236 0.008782794 *
4 Keyboard:Posture 0.6370236 0.008782794 *In this case, sphericity is violated, so we need to additionally apply the Greenhouse-Geisser correction or the less conservative Huyn-Feldt correction. Nevertheless, let’s look at the uncorrected ANOVA table. Later, we’ll compare it with the uncorrected version provided by the aov() function.
m$ANOVA Effect DFn DFd F p p<.05 ges
2 Keyboard 1 22 124.4151 1.596641e-10 * 0.6151917
3 Posture 2 44 381.4980 1.602465e-28 * 0.9255880
4 Keyboard:Posture 2 44 157.1600 9.162076e-21 * 0.8367128Note that “ges” in the ANOVA table is the generalized eta-squared measure of effect size, \(\eta^2_G\), preferred to eta-squared or partial eta-squared. See Roger Bakeman (2005) “Recommended effect size statistics for repeated measures designs”, Behavior Research Methods, 37 (3) pages 379–384. There, he points out that the usual \(\eta^2\) is the ratio of effect to total variance:
\[\eta^2=\frac{SS_{\text{effect}}}{SS_{\text{total}}}\]
where \(SS\) is sum of squares. This is similar to the \(R^2\) measure typically reported for regression results. The generalized version is alleged to compensate for the deficiencies that \(\eta^2\) shares with \(R^2\), mainly that it can be improved by simply adding more predictors. The generalized version looks like this:
\[\eta^2_G=\frac{SS_{\text{effect}}}{\delta \times SS_{\text{effect}} + \sum SS_{\text{measured}}}\]
Here \(\delta=0\) if the effect involves one or more measured factors and \(\delta=1\) if the effect involves only manipulated factors. (Actually it is a little more complicated—here I’m just trying to convey a crude idea that \(\eta^2_G\) ranges between 0 and 1 and that, as it approaches 1, the size of the effect is greater. Oddly enough, it is common to report effect sizes as simply small, medium, or large.)
Now compute the corrected degrees of freedom for each corrected effect.
pos <- match(m$'Sphericity Corrections'$Effect,
m$ANOVA$Effect) # positions of within-Ss efx in m$ANOVA
m$Sphericity$GGe.DFn <- m$Sphericity$GGe * m$ANOVA$DFn[pos] # Greenhouse-Geisser
m$Sphericity$GGe.DFd <- m$Sphericity$GGe * m$ANOVA$DFd[pos]
m$Sphericity$HFe.DFn <- m$Sphericity$HFe * m$ANOVA$DFn[pos] # Huynh-Feldt
m$Sphericity$HFe.DFd <- m$Sphericity$HFe * m$ANOVA$DFd[pos]
m$Sphericity Effect GGe p[GG] p[GG]<.05 HFe p[HF]
3 Posture 0.7336884 1.558280e-21 * 0.7731517 1.432947e-22
4 Keyboard:Posture 0.7336884 7.800756e-16 * 0.7731517 1.447657e-16
p[HF]<.05 GGe.DFn GGe.DFd HFe.DFn HFe.DFd
3 * 1.467377 32.28229 1.546303 34.01868
4 * 1.467377 32.28229 1.546303 34.01868The above table shows the Greenhouse Geisser correction to the numerator (GGe.DFn) and denominator (GGe.DFd) degrees of freedom and the resulting \(p\)-values (p[GG]). The Greenhouse Geiser epsilon statistic (\(\epsilon\)) is shown as GGe. There is an analogous set of measures for the less conservative Huynh-Feldt correction. Note that you could calculate a more conservative \(F\)-statistic using the degrees of freedom given even though a corrected \(F\)-statistic is not shown for some reason.
13.7 ANOVA results from aov()
The uncorrected results from the ez package are the same as the aov() function in base R, shown below.
m <- aov(WPM ~ Keyboard * Posture + Error(Subject/Posture),
data=mbltxt) # fit model
summary(m)
Error: Subject
Df Sum Sq Mean Sq F value Pr(>F)
Keyboard 1 96.35 96.35 124.4 1.6e-10 ***
Residuals 22 17.04 0.77
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: Subject:Posture
Df Sum Sq Mean Sq F value Pr(>F)
Posture 2 749.6 374.8 381.5 <2e-16 ***
Keyboard:Posture 2 308.8 154.4 157.2 <2e-16 ***
Residuals 44 43.2 1.0
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 113.7.1 Manual post hoc pairwise comparisons
Because the ANOVA table showed a significant interaction effect and the significance of that interaction effect was borne out by the small p[GG] value, it makes sense to conduct post hoc pairwise comparisons. These require reshaping the data to a wide format because the \(t\) test expects data in that format.
mbltxt.wide <- dcast(mbltxt, Subject + Keyboard ~ Posture,
value.var="WPM")
head(mbltxt.wide) Subject Keyboard Sit Stand Walk
1 1 iPhone 20.2145 23.7485 20.7960
2 2 iPhone 20.8805 23.2595 19.1305
3 3 iPhone 21.2635 23.4945 20.8545
4 4 iPhone 20.7080 23.9220 18.2575
5 5 iPhone 21.0075 23.4700 17.7105
6 6 iPhone 19.9115 24.2975 19.8550sit <- t.test(mbltxt.wide$Sit ~ Keyboard, data=mbltxt.wide)
std <- t.test(mbltxt.wide$Stand ~ Keyboard, data=mbltxt.wide)
wlk <- t.test(mbltxt.wide$Walk ~ Keyboard, data=mbltxt.wide)
p.adjust(c(sit$p.value, std$p.value, wlk$p.value), method="holm")[1] 3.842490e-10 4.622384e-08 1.450214e-11The above \(p\)-values indicate significant differences for all three.
13.7.2 Compare iPhone ‘sit’ and ‘walk’
par(pin=c(2.75,1.25),cex=0.5)
tst<-t.test(mbltxt.wide[mbltxt.wide$Keyboard == "iPhone",]$Sit,
mbltxt.wide[mbltxt.wide$Keyboard == "iPhone",]$Walk,
paired=TRUE)
tst
Paired t-test
data: mbltxt.wide[mbltxt.wide$Keyboard == "iPhone", ]$Sit and mbltxt.wide[mbltxt.wide$Keyboard == "iPhone", ]$Walk
t = 3.6259, df = 11, p-value = 0.003985
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
0.6772808 2.7695525
sample estimates:
mean difference
1.723417 par(pin=c(2.75,1.25),cex=0.5)
boxplot(mbltxt.wide[mbltxt.wide$Keyboard == "iPhone",]$Sit,
mbltxt.wide[mbltxt.wide$Keyboard == "iPhone",]$Walk,
xlab="iPhone.Sit vs. iPhone.Walk", ylab="WPM")
13.8 What if ANOVA assumptions aren’t met? (Nonparametric approach to factorial ANOVA)
The rest of this section concerns a nonparametric approach developed at the University of Washington.
13.8.1 The Aligned Rank Transform (ART) procedure
13.8.2 Explore the Error_Rate data
s <- mbltxt |>
group_by(Keyboard,Posture) |>
summarize(
WPM.median=median(Error_Rate),
WPM.mean=mean(Error_Rate),
WPM.sd=sd(Error_Rate)
)`summarise()` has grouped output by 'Keyboard'. You can override using the
`.groups` argument.s# A tibble: 6 × 5
# Groups: Keyboard [2]
Keyboard Posture WPM.median WPM.mean WPM.sd
<fct> <fct> <dbl> <dbl> <dbl>
1 Galaxy Sit 0.019 0.0194 0.00243
2 Galaxy Stand 0.0305 0.0307 0.00406
3 Galaxy Walk 0.0658 0.0632 0.00575
4 iPhone Sit 0.0205 0.0199 0.00248
5 iPhone Stand 0.0302 0.0298 0.00258
6 iPhone Walk 0.04 0.0399 0.0040513.8.3 Histograms of Error_Rate
ggplot(mbltxt,aes(Error_Rate,fill=Keyboard)) +
geom_histogram(bins=20,alpha=0.9,position="dodge",show.legend=FALSE) +
scale_color_brewer() +
scale_fill_brewer() +
facet_grid(Keyboard~Posture) +
theme_tufte(base_size=8)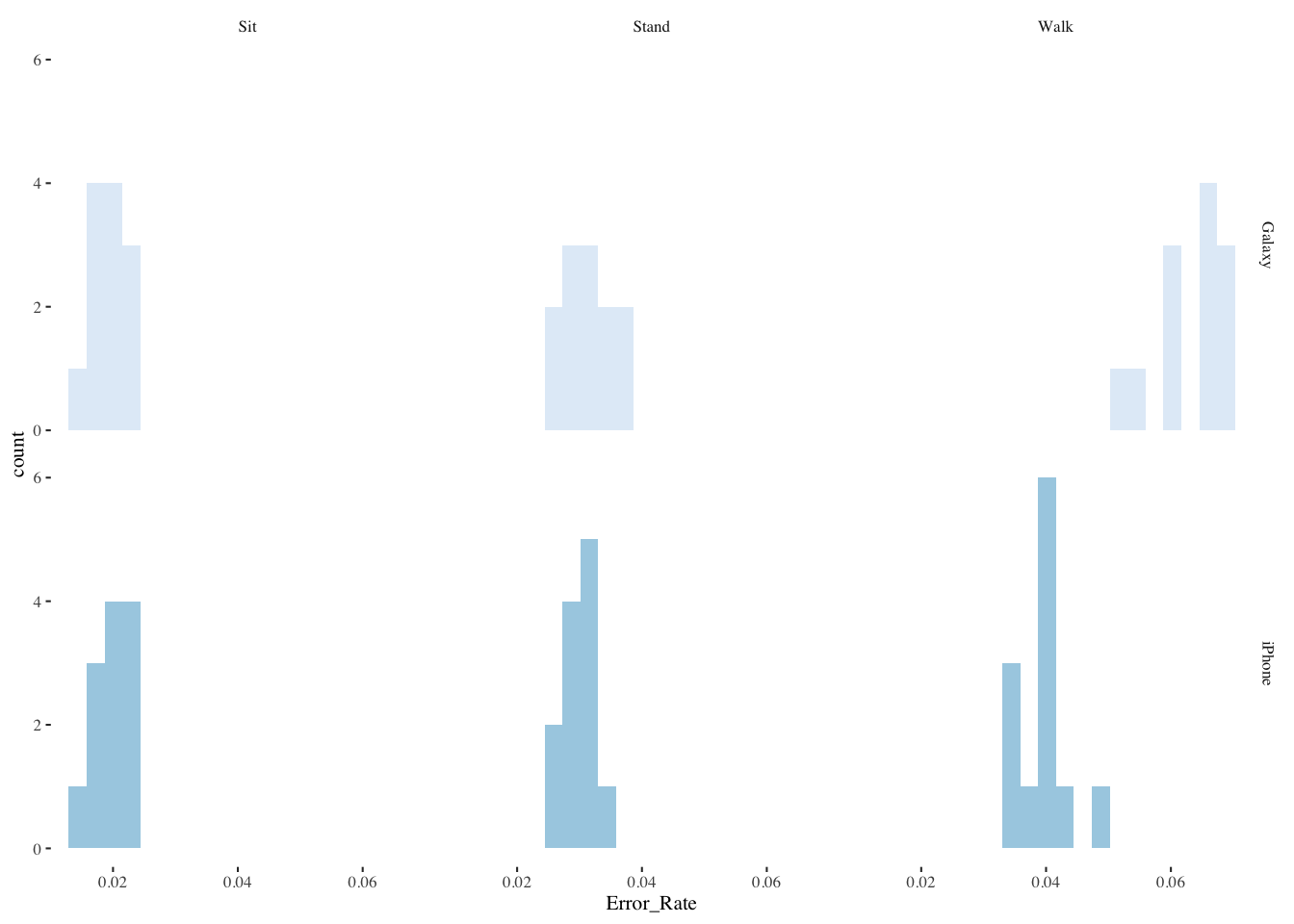
13.8.4 Box plots of Error_Rate
ggplot(mbltxt,aes(Keyboard,Error_Rate,fill=Keyboard)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Greens") +
facet_wrap(~Posture) +
theme_tufte(base_size=7)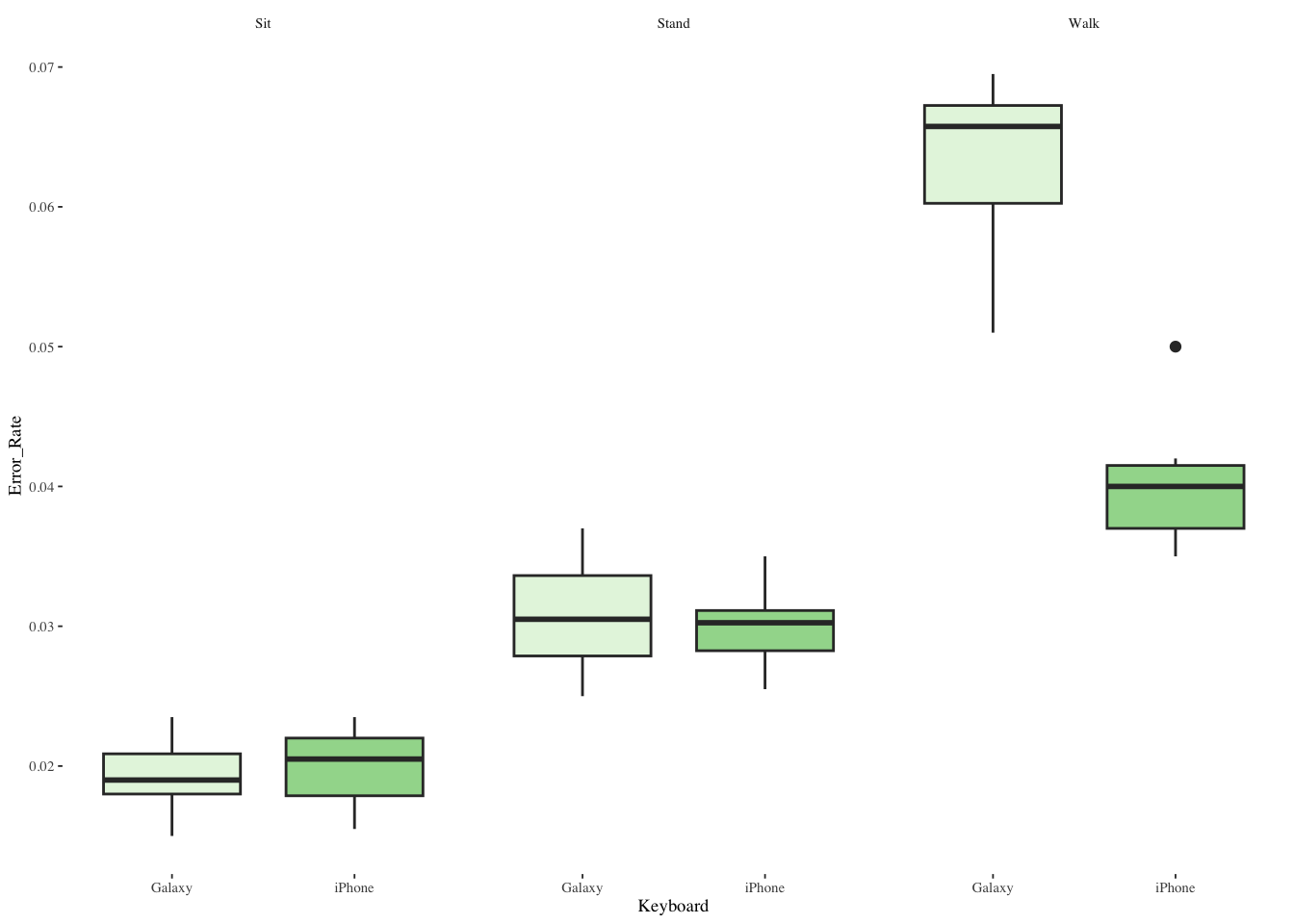
13.8.5 Interaction plot of Error_Rate
par(pin=c(2.75,1.25),cex=0.5)
with(mbltxt,
interaction.plot(Posture, Keyboard, Error_Rate,
ylim=c(0, max(mbltxt$Error_Rate))))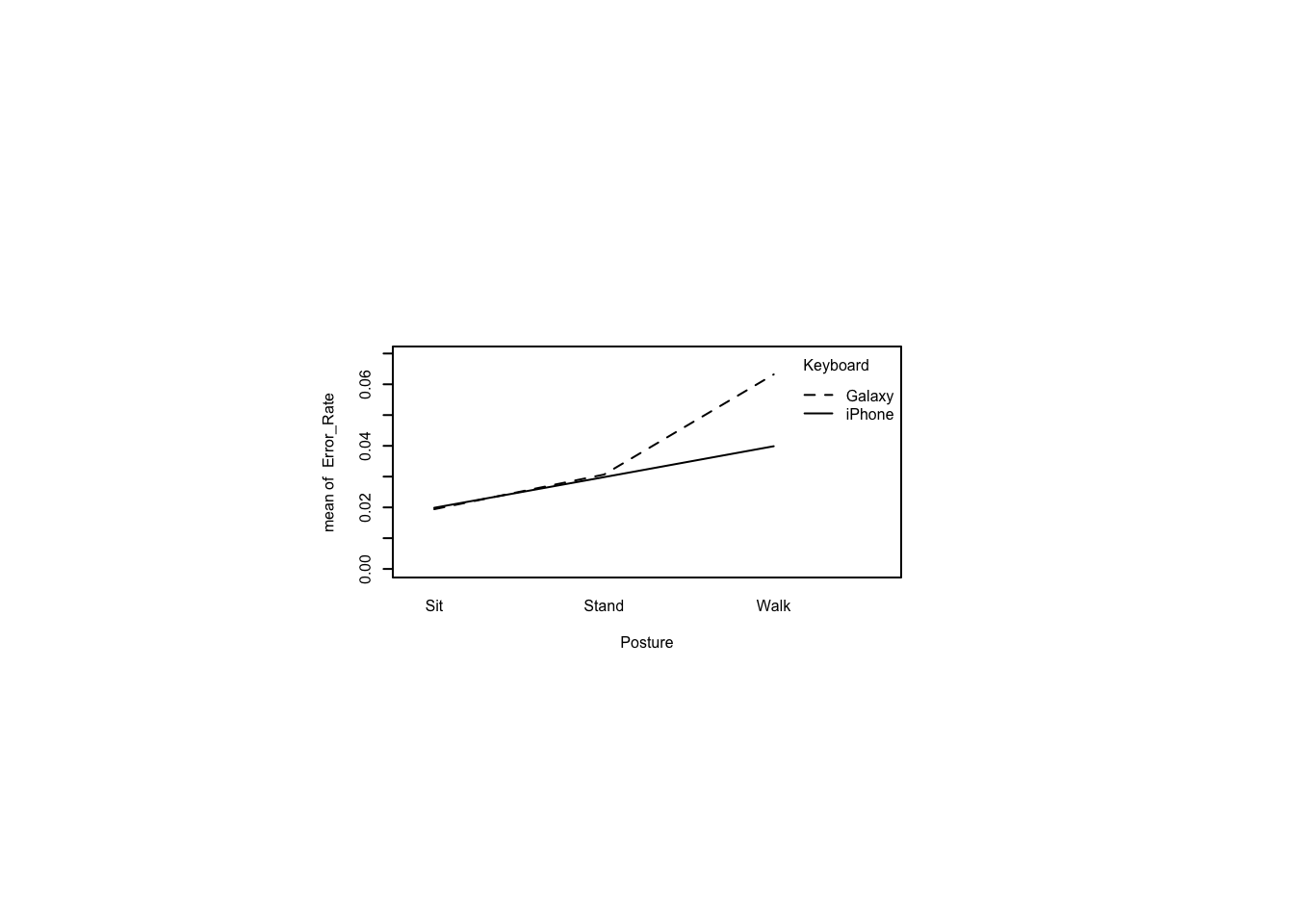
13.8.6 Aligned Rank Transform on Error_Rate
pacman::p_load(ARTool) # for art, artlm
m <- art(Error_Rate ~ Keyboard * Posture + (1|Subject), data=mbltxt) # uses LMM
anova(m) # report anovaboundary (singular) fit: see help('isSingular')Analysis of Variance of Aligned Rank Transformed Data
Table Type: Analysis of Deviance Table (Type III Wald F tests with Kenward-Roger df)
Model: Mixed Effects (lmer)
Response: art(Error_Rate)
F Df Df.res Pr(>F)
1 Keyboard 89.450 1 22 3.2959e-09 ***
2 Posture 274.704 2 44 < 2.22e-16 ***
3 Keyboard:Posture 78.545 2 44 3.0298e-15 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 13.8.7 Examine the normality assumption
par(pin=c(2.75,1.25),cex=0.5)
shapiro.test(residuals(m)) # normality?
Shapiro-Wilk normality test
data: residuals(m)
W = 0.98453, p-value = 0.5227qqnorm(residuals(m)); qqline(residuals(m)) # seems to conform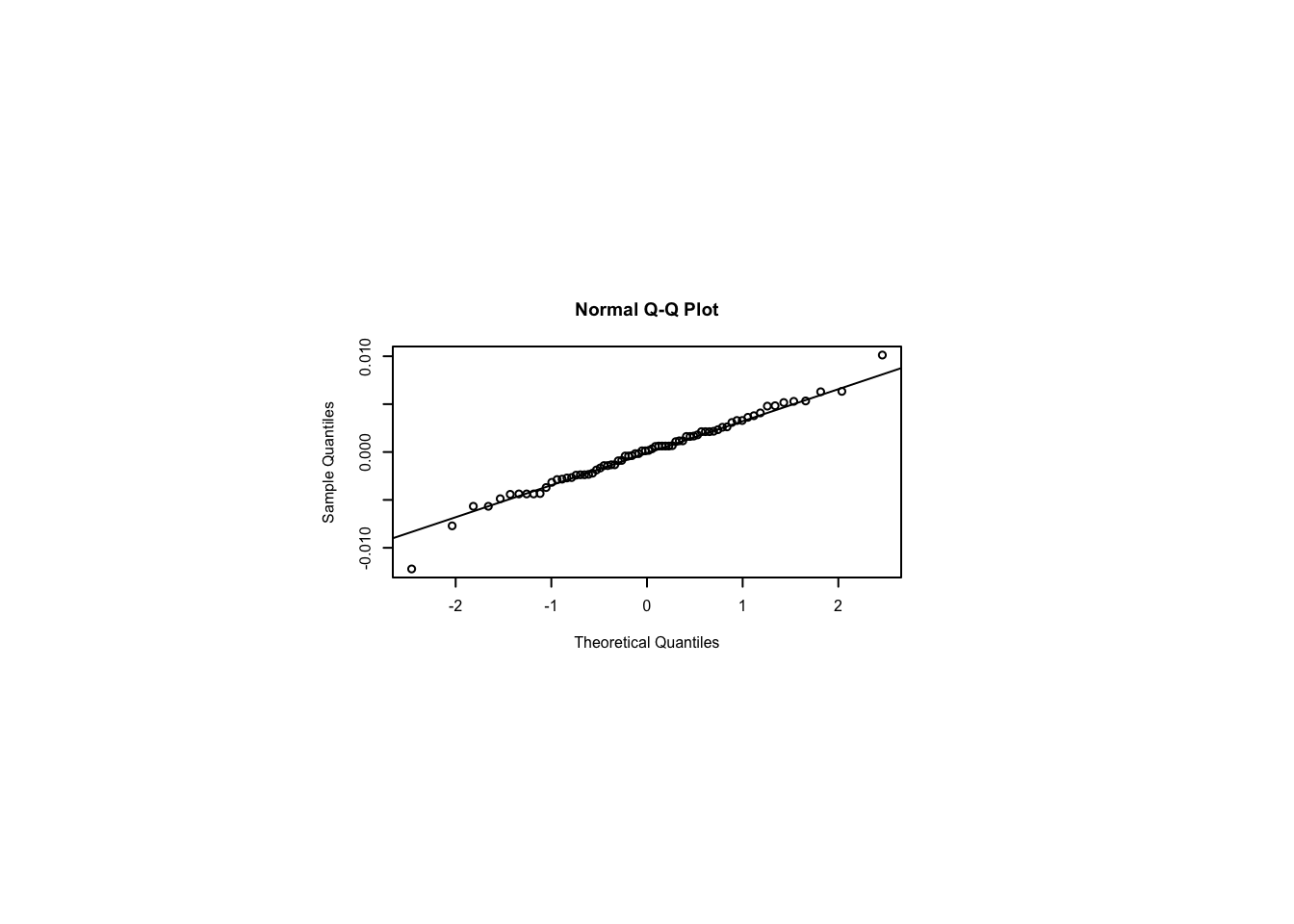
13.8.8 Interaction plot
par(pin=c(2.75,1.25),cex=0.5)
with(mbltxt,
interaction.plot(Posture, Keyboard, Error_Rate,
ylim=c(0, max(mbltxt$Error_Rate)))) # for convenience
13.8.9 Conduct post hoc pairwise comparisons within each factor
#. pacman::p_load(emmeans) # instead of lsmeans
#. for backward compatibility, emmeans provides an lsmeans() function
lsmeans(artlm(m, "Keyboard"), pairwise ~ Keyboard)NOTE: Results may be misleading due to involvement in interactions$lsmeans
Keyboard lsmean SE df lower.CL upper.CL
Galaxy 52.3 2.36 22 47.4 57.2
iPhone 20.7 2.36 22 15.8 25.6
Results are averaged over the levels of: Posture
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95
$contrasts
contrast estimate SE df t.ratio p.value
Galaxy - iPhone 31.6 3.34 22 9.458 <.0001
Results are averaged over the levels of: Posture
Degrees-of-freedom method: kenward-roger lsmeans(artlm(m, "Posture"), pairwise ~ Posture)NOTE: Results may be misleading due to involvement in interactions$lsmeans
Posture lsmean SE df lower.CL upper.CL
Sit 12.5 1.47 65.9 9.57 15.4
Stand 36.5 1.47 65.9 33.57 39.4
Walk 60.5 1.47 65.9 57.57 63.4
Results are averaged over the levels of: Keyboard
Degrees-of-freedom method: kenward-roger
Confidence level used: 0.95
$contrasts
contrast estimate SE df t.ratio p.value
Sit - Stand -24 2.05 44 -11.720 <.0001
Sit - Walk -48 2.05 44 -23.439 <.0001
Stand - Walk -24 2.05 44 -11.720 <.0001
Results are averaged over the levels of: Keyboard
Degrees-of-freedom method: kenward-roger
P value adjustment: tukey method for comparing a family of 3 estimates #. Warning: don't do the following in ART!
#lsmeans(artlm(m, "Keyboard : Posture"), pairwise ~ Keyboard : Posture)The above contrast-testing method is invalid for cross-factor pairwise comparisons in ART. and you can’t just grab aligned-ranks for manual \(t\)-tests. instead, use testInteractions() from the phia package to perform “interaction contrasts.” See vignette("art-contrasts").
pacman::p_load(phia)
testInteractions(artlm(m, "Keyboard:Posture"),
pairwise=c("Keyboard", "Posture"), adjustment="holm")boundary (singular) fit: see help('isSingular')Chisq Test:
P-value adjustment method: holm
Value SE Df Chisq Pr(>Chisq)
Galaxy-iPhone : Sit-Stand -5.083 6.8028 1 0.5584 0.4549
Galaxy-iPhone : Sit-Walk -76.250 6.8028 1 125.6340 <2e-16 ***
Galaxy-iPhone : Stand-Walk -71.167 6.8028 1 109.4412 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1In the output, A-B : C-D is interpreted as a difference-of-differences, i.e., the difference between (A-B | C) and (A-B | D). In words, is the difference between A and B significantly different in condition C from condition D?
13.9 Experiments with interaction effects
This section reports on three experiments with possible interaction effects: Avatars, Notes, and Social media value. To work through the questions, you need the three csv files containing the data: avatars.csv, notes.csv, and socialvalue.csv.
These experiments may be between-subjects, within-subjects, or mixed. To be a mixed factorial design, there would have to be at least two independent variables and at least one within-subjects factor and at least one between-subjects factor.
13.9.1 Sentiments about Avatars among males and females (Interaction effects)
Thirty males and thirty females were shown an avatar that was either male or female and asked to write a story about that avatar. The number of positive sentiments in the story were summed. What kind of experimental design is this? [Answer: It is a \(2\times 2\) between-subjects design with factors for Sex (M, F) and Avatar (M, F).]
avatars <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/avatars.csv"))
avatars$Subject <- factor(avatars$Subject)
summary(avatars) Subject Sex Avatar Positives
1 : 1 Length:60 Length:60 Min. : 32.0
2 : 1 Class :character Class :character 1st Qu.: 65.0
3 : 1 Mode :character Mode :character Median : 84.0
4 : 1 Mean : 85.1
5 : 1 3rd Qu.:104.2
6 : 1 Max. :149.0
(Other):54 What’s the average number of positive sentiments for the most positive combination of Sex and Avatar?
plyr::ddply(avatars,~Sex*Avatar,summarize,
Pos.mean=mean(Positives),
Pos.sd=sd(Positives)) Sex Avatar Pos.mean Pos.sd
1 Female Female 63.13333 17.48414
2 Female Male 85.20000 25.31008
3 Male Female 100.73333 18.72152
4 Male Male 91.33333 19.66384Create an interaction plot with Sex on the X-Axis and Avatar as the traces. Do the lines cross? Do the same for reversed axes.
par(pin=c(2.75,1.25),cex=0.5)
with(avatars,interaction.plot(Sex,Avatar,Positives,
ylim=c(0,max(avatars$Positives))))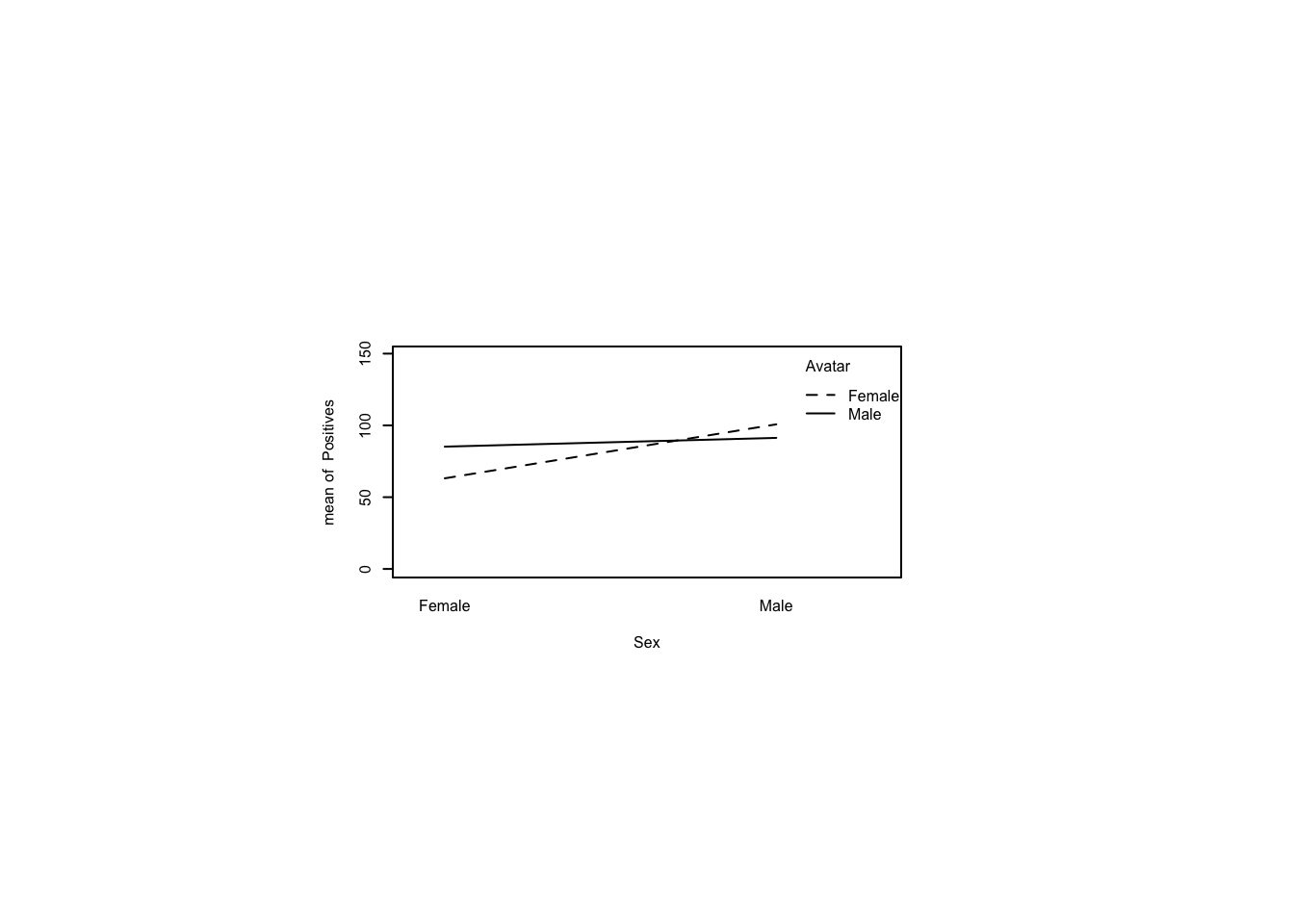
with(avatars,interaction.plot(Avatar,Sex,Positives,
ylim=c(0,max(avatars$Positives))))
Conduct a factorial ANOVA on Positives by Sex and Avatar and report the largest \(F\)-statistic. Report which effects are significant.
m<-ezANOVA(dv=Positives,between=c(Sex,Avatar),
wid=Subject,data=avatars)Warning: Converting "Sex" to factor for ANOVA.Warning: Converting "Avatar" to factor for ANOVA.Coefficient covariances computed by hccm()m$ANOVA Effect DFn DFd F p p<.05 ges
1 Sex 1 56 17.041756 0.0001228287 * 0.23331526
2 Avatar 1 56 1.429598 0.2368686270 0.02489305
3 Sex:Avatar 1 56 8.822480 0.0043757511 * 0.13610216Conduct planned pairwise comparisons using independent-samples \(t\)-tests. Ask whether females produced different numbers of positive sentiments for male vs female avatars. Then ask whether males did the same. Assume equal variances and use Holm’s sequential Bonferroni procedure to correct for multiple comparisons.
f<-t.test(avatars[avatars$Sex=="Female" & avatars$Avatar=="Male",]$Positives,
avatars[avatars$Sex=="Female" & avatars$Avatar=="Female",]$Positives,
var.equal=TRUE)
f
Two Sample t-test
data: avatars[avatars$Sex == "Female" & avatars$Avatar == "Male", ]$Positives and avatars[avatars$Sex == "Female" & avatars$Avatar == "Female", ]$Positives
t = 2.7782, df = 28, p-value = 0.009647
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
5.796801 38.336533
sample estimates:
mean of x mean of y
85.20000 63.13333 m<-t.test(avatars[avatars$Sex=="Male" & avatars$Avatar=="Male",]$Positives,
avatars[avatars$Sex=="Male" & avatars$Avatar=="Female",]$Positives,
var.equal=TRUE)
m
Two Sample t-test
data: avatars[avatars$Sex == "Male" & avatars$Avatar == "Male", ]$Positives and avatars[avatars$Sex == "Male" & avatars$Avatar == "Female", ]$Positives
t = -1.3409, df = 28, p-value = 0.1907
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-23.759922 4.959922
sample estimates:
mean of x mean of y
91.33333 100.73333 p.adjust(c(f$p.value,m$p.value),method="holm")[1] 0.01929438 0.1907346813.9.2 Writing notes with builtin or addon apps on two phones (mixed factorial design)
The notes.csv file describes a study in which iPhone and Android owners used a built-in note-taking app then a third-party note-taking app or vice versa. What kind of experimental design is this? (Answer: A \(2 \times 2\) mixed factorial design with a between-subjects factor for Phone (iPhone, Android) and a within-subjects factor for Notes (Built-in, Add-on).)
notes <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/notes.csv"))
notes$Subject<-factor(notes$Subject)
notes$Order<-factor(notes$Order)
summary(notes) Subject Phone Notes Order Words
1 : 2 Length:40 Length:40 1:20 Min. :259.0
2 : 2 Class :character Class :character 2:20 1st Qu.:421.8
3 : 2 Mode :character Mode :character Median :457.0
4 : 2 Mean :459.2
5 : 2 3rd Qu.:518.5
6 : 2 Max. :598.0
(Other):28 What’s the average number of words recorded for the most heavily used combination of Phone and Notes?
plyr::ddply(notes, ~Phone*Notes,summarize,
Words.mean=mean(Words),Words.sd=sd(Words)) Phone Notes Words.mean Words.sd
1 Android Add-on 388.1 42.38828
2 Android Built-in 410.9 77.49043
3 iPhone Add-on 504.2 47.29529
4 iPhone Built-in 533.7 48.04176Create an interaction plot with Phone on the X-Axis and Notes as the traces. Do the lines cross? Do the same for reversed axes.
par(pin=c(2.75,1.25),cex=0.5)
with(notes,interaction.plot(Phone,Notes,Words,
ylim=c(0,max(notes$Words))))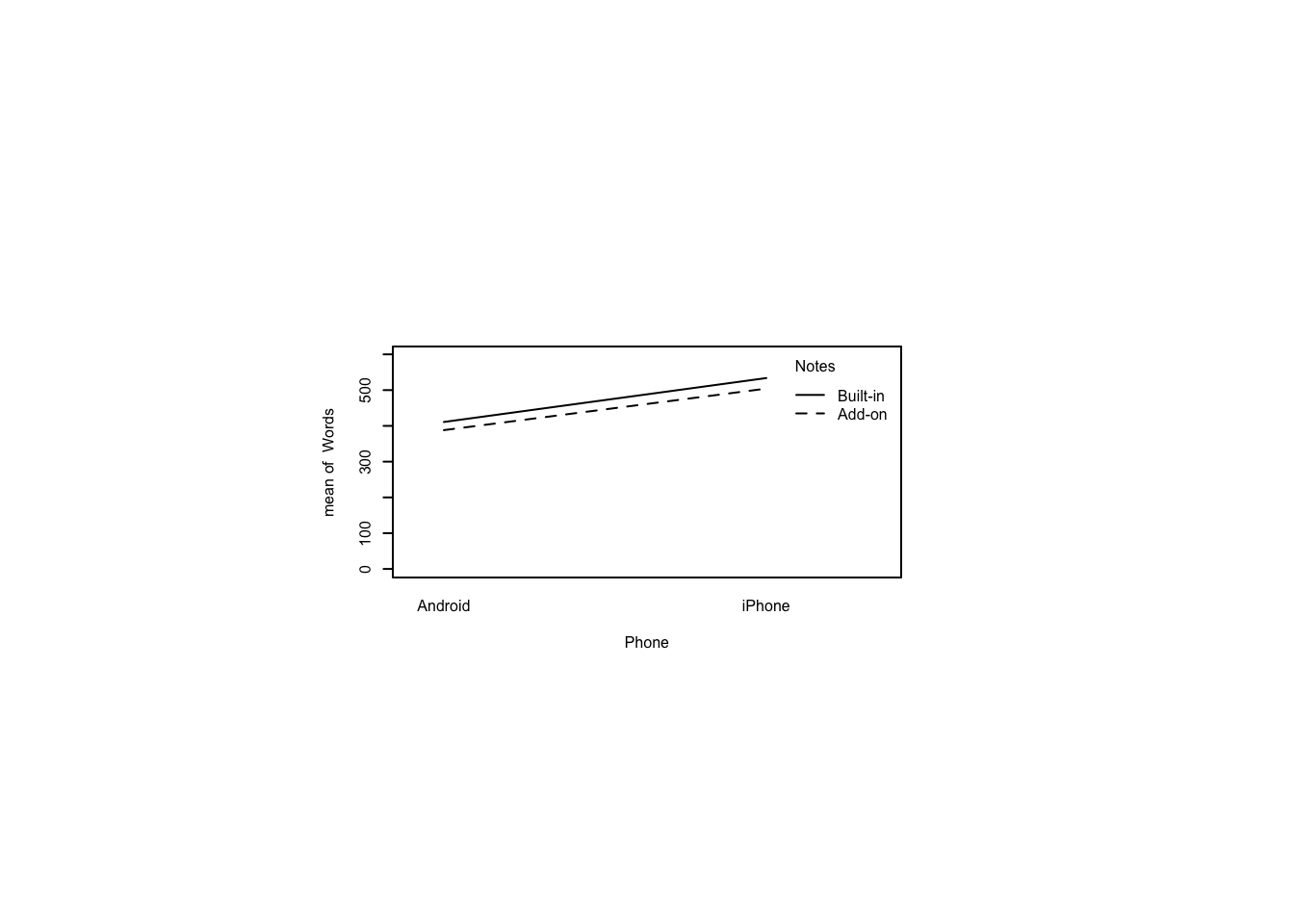
with(notes,interaction.plot(Notes,Phone,Words,
ylim=c(0,max(notes$Words))))
Test for an order effect in the presentation of order of the Notes factor. Report the \(p\)-value.
m<-ezANOVA(dv=Words,between=Phone,within=Order,wid=Subject,data=notes)Warning: Converting "Phone" to factor for ANOVA.m$ANOVA Effect DFn DFd F p p<.05 ges
2 Phone 1 18 43.5625695 3.375888e-06 * 0.56875437
3 Order 1 18 0.5486763 4.684126e-01 0.01368098
4 Phone:Order 1 18 3.0643695 9.705122e-02 0.07189858Conduct a factorial ANOVA on Words by Phone and Notes. Report the largest \(F\)-statistic.
m<-ezANOVA(dv=Words,between=Phone,within=Notes,wid=Subject,data=notes)Warning: Converting "Notes" to factor for ANOVA.Warning: Converting "Phone" to factor for ANOVA.m$ANOVA Effect DFn DFd F p p<.05 ges
2 Phone 1 18 43.56256949 3.375888e-06 * 0.562185697
3 Notes 1 18 2.35976941 1.418921e-01 0.057972811
4 Phone:Notes 1 18 0.03872717 8.461951e-01 0.001008948Conduct paired-samples \(t\)-tests to answer two questions. First, did iPhone user enter different numbers of words using the built-in notes app versus the add-on notes app? Second, same for Android. Assume equal variances and use Holm’s sequential Bonferroni procedure to correct for multiple comparisons. Report the lowest adjusted \(p\)-value.
notes.wide<-dcast(notes,Subject+Phone~Notes,value.var="Words")
head(notes.wide) Subject Phone Add-on Built-in
1 1 iPhone 464 561
2 2 Android 433 428
3 3 iPhone 598 586
4 4 Android 347 448
5 5 iPhone 478 543
6 6 Android 365 445i<-t.test(notes.wide[notes.wide$Phone=="iPhone",]$'Add-on',
notes.wide[notes.wide$Phone=="iPhone",]$'Built-in',
paired=TRUE,var.equal=TRUE)
i
Paired t-test
data: notes.wide[notes.wide$Phone == "iPhone", ]$"Add-on" and notes.wide[notes.wide$Phone == "iPhone", ]$"Built-in"
t = -1.8456, df = 9, p-value = 0.09804
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-65.658758 6.658758
sample estimates:
mean difference
-29.5 a<-t.test(notes.wide[notes.wide$Phone=="Android",]$'Add-on',
notes.wide[notes.wide$Phone=="Android",]$'Built-in',
paired=TRUE,var.equal=TRUE)
a
Paired t-test
data: notes.wide[notes.wide$Phone == "Android", ]$"Add-on" and notes.wide[notes.wide$Phone == "Android", ]$"Built-in"
t = -0.75847, df = 9, p-value = 0.4676
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-90.80181 45.20181
sample estimates:
mean difference
-22.8 p.adjust(c(i$p.value,a$p.value),method="holm")[1] 0.1960779 0.467567413.10 What if errors are not normally distributed? (Generalized linear models)
Here are three examples of generalized linear models. The first is analyzed using nominal logistic regression, the second is analyzed via ordinal logistic regression, and the third is analyzed via Poisson regression.
As Wikipedia tells us, a generalized linear model or GLM is a flexible generalization of ordinary linear regression that allows for response variables with error distribution models other than a normal distribution. There is also something called a general linear model but it is not the same thing as a generalized linear model. It is just the general form of the ordinary linear regression model: \(\mathbfit{Y=X\beta+\epsilon}\).
GLMs that we examine here are good for between-subjects studies so we’ll actually recode one of our fictitious data sets to be between subjects just to have an example to use.
13.10.1 Preferences among websites by males and females (GLM 1: Nominal logistic regression for preference responses)
13.10.2 Multinomial distribution with logit link function
The prefsABCsex.csv file records preferences among three websites A, B, and C expressed by males and females. The subject number, preference and sex were recorded.
The logit link function is the log odds function, generally \(\text{logit}(p)=\ln \frac{p}{1-p}\), where \(p\) is the probability of an event such as choosing website A. The form of the link function is \(\mathbfit{X\beta}=\ln\frac{\mu}{1-\mu}\). This is just the relationship of a matrix of predictors times a vector of parameters \(\mathbfit{\beta}\) to the logit of the mean of the distribution.
prefsABCsex <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/prefsABCsex.csv"))
head(prefsABCsex)# A tibble: 6 × 3
Subject Pref Sex
<dbl> <chr> <chr>
1 1 C F
2 2 C M
3 3 B M
4 4 C M
5 5 C M
6 6 B F prefsABCsex$Subject<-factor(prefsABCsex$Subject)
prefsABCsex$Sex<-factor(prefsABCsex$Sex)
summary(prefsABCsex) Subject Pref Sex
1 : 1 Length:60 F:29
2 : 1 Class :character M:31
3 : 1 Mode :character
4 : 1
5 : 1
6 : 1
(Other):54 ggplot(prefsABCsex[prefsABCsex$Sex == "M",],aes(Pref)) +
theme_tufte() +
geom_bar(width=0.25,fill="gray") +
geom_hline(yintercept=seq(0, 20, 5), col="white", lwd=1) +
annotate("text", x = 1.5, y = 18, adj=1, family="serif",
label = c("Males prefer\nwebsite C"))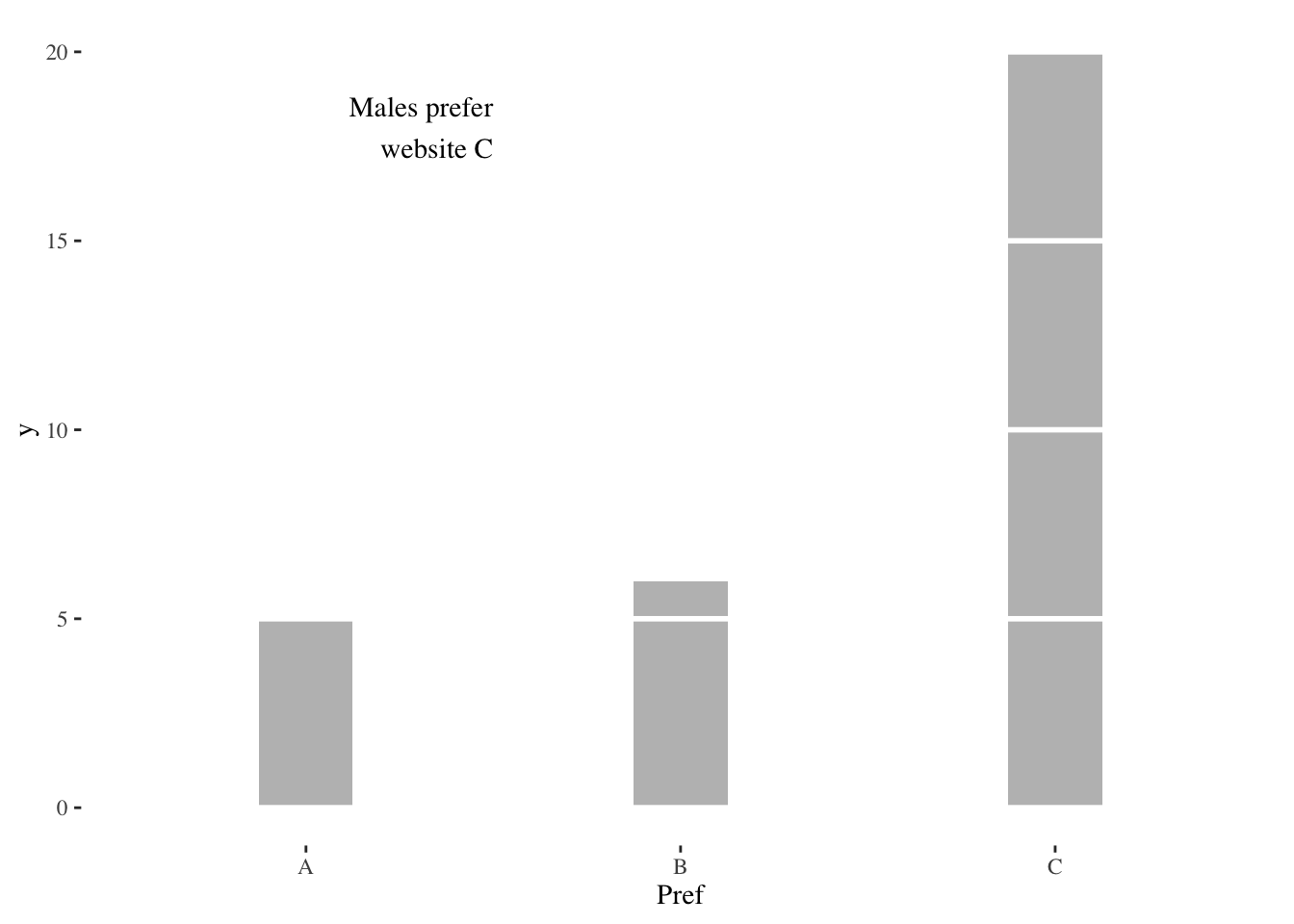
ggplot(prefsABCsex[prefsABCsex$Sex == "F",],aes(Pref)) +
theme_tufte() +
geom_bar(width=0.25,fill="gray") +
geom_hline(yintercept=seq(0, 20, 5), col="white", lwd=1) +
annotate("text", x = 1.5, y = 18, adj=1, family="serif",
label = c("Females dislike\nwebsite A"))
These histograms lead us to suspect that C is preferred by males and that A is disliked by females, but we should still run tests to be convinced that the variability observed is not due to chance.
Analyze Pref by Sex using multinomial logistic regression, aka nominal logistic regression. Here we are testing for whether there is a difference between the sexes regarding their preferences.
The annotation type=3 is borrowed from SAS and refers to one of three ways of handling an unbalanced design. This experimental design is unbalanced because there are more males than females being tested. This way of handling the unbalanced design is only valid if there are significant interactions, as hinted by the gross differences between the preceding histograms.
pacman::p_load(nnet) # provides multinom()
#. pacman::p_load(car) # provides Anova()
#. set sum-to-zero contrasts for the Anova call
contrasts(prefsABCsex$Sex) <- "contr.sum"
m<-multinom(Pref~Sex, data=prefsABCsex)# weights: 9 (4 variable)
initial value 65.916737
iter 10 value 55.099353
iter 10 value 55.099353
final value 55.099353
convergedAnova(m, type=3)Analysis of Deviance Table (Type III tests)
Response: Pref
LR Chisq Df Pr(>Chisq)
Sex 7.0744 2 0.02909 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The Analysis of Deviance table tells us that there is a significant main effect for Sex. It does not tell us more detail but motivates pairwise tests to get more detail. If there were no significant effect, pairwise tests would not be warranted.
Pairwise tests tell which of the bins are over or under populated based on the assumption that each bin should contain one third of the observations (hence p=1/3). When making multiple comparisons we would overstate the significance of the differences so we use Holm’s sequential Bonferroni procedure to correct this.
ma<-binom.test(sum(prefsABCsex[prefsABCsex$Sex == "M",]$Pref == "A"),
nrow(prefsABCsex[prefsABCsex$Sex == "M",]), p=1/3)
mb<-binom.test(sum(prefsABCsex[prefsABCsex$Sex == "M",]$Pref == "B"),
nrow(prefsABCsex[prefsABCsex$Sex == "M",]), p=1/3)
mc<-binom.test(sum(prefsABCsex[prefsABCsex$Sex == "M",]$Pref == "C"),
nrow(prefsABCsex[prefsABCsex$Sex == "M",]), p=1/3)
#. correct for multiple comparisons
p.adjust(c(ma$p.value, mb$p.value, mc$p.value), method="holm")[1] 0.109473564 0.126622172 0.001296754fa<-binom.test(sum(prefsABCsex[prefsABCsex$Sex == "F",]$Pref == "A"),
nrow(prefsABCsex[prefsABCsex$Sex == "F",]), p=1/3)
fb<-binom.test(sum(prefsABCsex[prefsABCsex$Sex == "F",]$Pref == "B"),
nrow(prefsABCsex[prefsABCsex$Sex == "F",]), p=1/3)
fc<-binom.test(sum(prefsABCsex[prefsABCsex$Sex == "F",]$Pref == "C"),
nrow(prefsABCsex[prefsABCsex$Sex == "F",]), p=1/3)
#. correct for multiple comparisons
p.adjust(c(fa$p.value, fb$p.value, fc$p.value), method="holm")[1] 0.02703274 0.09447821 0.69396951The preceding tests confirm what we suspected from looking at histograms: males prefer C and females dislike A. We see this by looking at the adjusted \(p\)-values, where the first row, third value is significant and the second row, first value is significant.
How would we write this up in a report? We could make the following claim. We tested the main effect for sex and found a significant result, \(\chi^2_2=7.1, p<0.05\). An exact binomial test found the preference among males for website C greater than chance, \(p<0.01\). An exact binomial test found the preference among females against website A greater than chance, \(p<0.05\). No other significant differences were found.
13.10.3 Judgments of perceived effort (GLM 2: Ordinal logistic regression for Likert responses)
13.10.4 Multinomial distribution with cumulative logit link function
In this example, users are either searching, scrolling or using voice to find contacts in a smartphone address book. The time it takes to find a certain number of contacts, the perceived effort, and the number of errors are all recorded. Of interest now is the perceived effort, recorded on a Likert scale. A Likert scale can not be normally distributed because of the restrictions on the ends and is not likely to even look vaguely normal.
The cumulative logit link function is like the logit link function:
\[\text{logit}(P(Y\leqslant j|x))=\ln\frac{P(Y\leqslant j|x)}{1-P(Y\leqslant j|x)} \text{ where }Y=1,2,\ldots,J\]
In this case \(J\) ranges from 1 to 7.
Read in the data and examine it. We see that it is a within-subjects study but it is a fictitious study anyway so we will recode it as if it were a between-subjects study. Then we will be able to apply the following techniques, which we would have to modify for a within-subjects study.
srchscrlvce <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/srchscrlvce.csv"))
head(srchscrlvce)# A tibble: 6 × 6
Subject Technique Order Time Errors Effort
<dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 1 Search 1 98 4 5
2 1 Scroll 2 152 0 6
3 2 Search 2 57 2 2
4 2 Scroll 1 148 0 3
5 3 Search 1 86 3 2
6 3 Scroll 2 160 0 4srchscrlvce$Subject<-(1:nrow(srchscrlvce)) # recode as between-subjects
srchscrlvce$Subject<-factor(srchscrlvce$Subject)
srchscrlvce$Technique<-factor(srchscrlvce$Technique)
srchscrlvce$Order<-NULL # drop order, n/a for between-subjects
head(srchscrlvce) # verify# A tibble: 6 × 5
Subject Technique Time Errors Effort
<fct> <fct> <dbl> <dbl> <dbl>
1 1 Search 98 4 5
2 2 Scroll 152 0 6
3 3 Search 57 2 2
4 4 Scroll 148 0 3
5 5 Search 86 3 2
6 6 Scroll 160 0 4summary(srchscrlvce) Subject Technique Time Errors Effort
1 : 1 Scroll:20 Min. : 49.0 Min. :0.00 Min. :1.00
2 : 1 Search:20 1st Qu.: 86.0 1st Qu.:1.00 1st Qu.:3.00
3 : 1 Voice :20 Median : 97.0 Median :2.00 Median :4.00
4 : 1 Mean :106.2 Mean :2.75 Mean :4.15
5 : 1 3rd Qu.:128.0 3rd Qu.:4.00 3rd Qu.:5.00
6 : 1 Max. :192.0 Max. :9.00 Max. :7.00
(Other):54 A good description of Effort is the median and quantiles. Another good description is the mean and standard deviation.
plyr::ddply(srchscrlvce, ~ Technique,
function(data) summary(data$Effort)) Technique Min. 1st Qu. Median Mean 3rd Qu. Max.
1 Scroll 1 3.00 4 4.40 6.00 7
2 Search 1 3.00 4 3.60 4.25 5
3 Voice 1 3.75 5 4.45 5.25 6plyr::ddply(srchscrlvce, ~ Technique,
summarize, Effort.mean=mean(Effort), Effort.sd=sd(Effort)) Technique Effort.mean Effort.sd
1 Scroll 4.40 1.698296
2 Search 3.60 1.187656
3 Voice 4.45 1.356272par(cex=0.6)
ggplot(srchscrlvce,aes(Effort,fill=Technique)) +
geom_histogram(bins=7,alpha=0.8,position="dodge") +
scale_color_grey() +
scale_fill_grey() +
theme_tufte()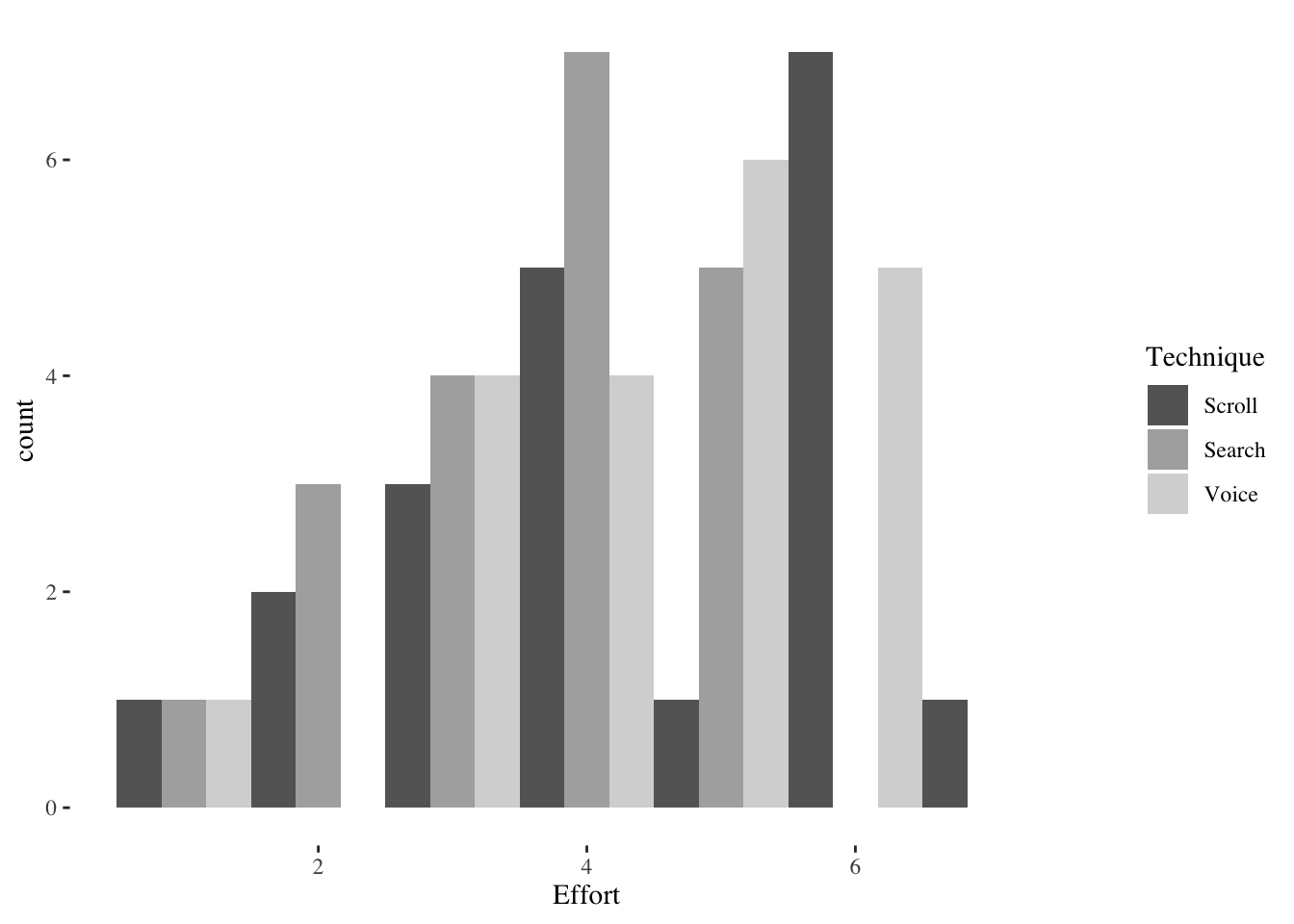
ggplot(srchscrlvce,aes(Technique,Effort,fill=Technique)) +
geom_tufteboxplot(show.legend=FALSE) +
theme_tufte()Warning: The following aesthetics were dropped during statistical transformation: y
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?Warning: Using the `size` aesthetic in this geom was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` in the `default_aes` field and elsewhere instead.Warning: Using the `size` aesthetic with geom_segment was deprecated in ggplot2 3.4.0.
ℹ Please use the `linewidth` aesthetic instead.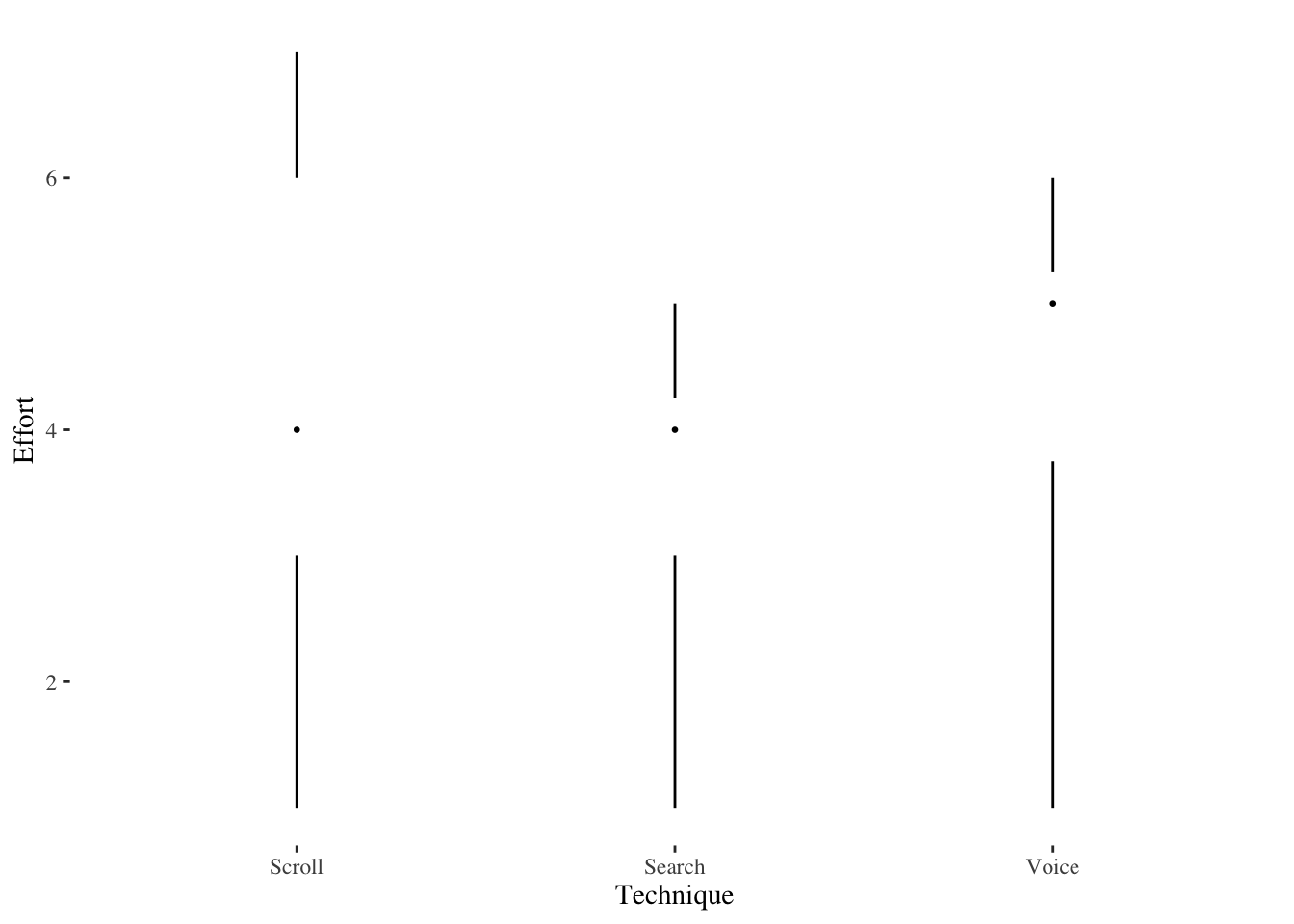
The boxplots (these are Tufte-style boxplots) are not encouraging. We may not find a significant difference among these three techniques but let us try anyway. We analyze Effort Likert ratings by Technique using ordinal logistic regression.
#. pacman::p_load(MASS) # provides polr()
#. pacman::p_load(car) # provides Anova()
srchscrlvce$Effort <- ordered(srchscrlvce$Effort)
#. set sum-to-zero contrasts for the Anova call
contrasts(srchscrlvce$Technique) <- "contr.sum"
m <- polr(Effort ~ Technique, data=srchscrlvce, Hess=TRUE) # ordinal logistic
Anova(m, type=3)Analysis of Deviance Table (Type III tests)
Response: Effort
LR Chisq Df Pr(>Chisq)
Technique 4.5246 2 0.1041Post hoc pairwise comparisons are NOT justified due to lack of significance but here’s how we would do them, just for completeness. Tukey means to compare all pairs and holm is the adjustment due to the double-counting that overstates the significance.
summary(glht(m, mcp(Technique="Tukey")), test=adjusted(type="holm"))
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: polr(formula = Effort ~ Technique, data = srchscrlvce, Hess = TRUE)
Linear Hypotheses:
Estimate Std. Error z value Pr(>|z|)
Search - Scroll == 0 -1.016610 0.584614 -1.739 0.191
Voice - Scroll == 0 0.007397 0.587700 0.013 0.990
Voice - Search == 0 1.024007 0.552298 1.854 0.191
(Adjusted p values reported -- holm method)How would we express this in a report? We would simply say that we found no significant differences between the three techniques.
13.10.5 Counting errors in a task (GLM 3: Poisson regression for count responses)
13.10.6 Poisson distribution with log link function
Using the same data but now focus on the Errors column instead of effort. Errors likely have a Poisson distribution. The log link function is just \(\mathbfit{X\beta}=\ln(\mu)\) rather than the more elaborate logit link function we saw before.
plyr::ddply(srchscrlvce, ~ Technique,
function(data) summary(data$Errors)) Technique Min. 1st Qu. Median Mean 3rd Qu. Max.
1 Scroll 0 0.00 0.5 0.70 1.00 2
2 Search 1 2.00 2.5 2.50 3.00 4
3 Voice 2 3.75 5.0 5.05 6.25 9plyr::ddply(srchscrlvce, ~ Technique, summarize,
Errors.mean=mean(Errors), Errors.sd=sd(Errors)) Technique Errors.mean Errors.sd
1 Scroll 0.70 0.8013147
2 Search 2.50 1.0513150
3 Voice 5.05 1.9049796par(cex=0.6)
ggplot(srchscrlvce,aes(Errors,fill=Technique)) +
geom_histogram(bins=9,alpha=0.8,position="dodge") +
scale_color_grey() +
scale_fill_grey() +
theme_tufte()
ggplot(srchscrlvce,aes(Technique,Errors,fill=Technique)) +
geom_boxplot(show.legend=FALSE) +
scale_fill_brewer(palette="Greens") +
theme_tufte()
These boxplots are very encouraging. There appears to be a clear difference between all three of these techniques. Notice that you could draw horizontal lines across the plot without intersecting the boxes. That represents a high degree of separation.
Now verify that these data are Poisson-distributed with a goodness-of-fit test for each technique. If the results are not significant, we expect that the data do not deviate significantly from what we would expect of a Poisson distribution.
#. pacman::p_load(fitdistrplus)
fit<-fitdist(srchscrlvce[srchscrlvce$Technique == "Search",]$Errors,
"pois", discrete=TRUE)
gofstat(fit)Chi-squared statistic: 1.522231
Degree of freedom of the Chi-squared distribution: 2
Chi-squared p-value: 0.4671449
the p-value may be wrong with some theoretical counts < 5
Chi-squared table:
obscounts theocounts
<= 1 4.000000 5.745950
<= 2 6.000000 5.130312
<= 3 6.000000 4.275260
> 3 4.000000 4.848477
Goodness-of-fit criteria
1-mle-pois
Akaike's Information Criterion 65.61424
Bayesian Information Criterion 66.60997fit<-fitdist(srchscrlvce[srchscrlvce$Technique == "Scroll",]$Errors,
"pois", discrete=TRUE)
gofstat(fit)Chi-squared statistic: 0.3816087
Degree of freedom of the Chi-squared distribution: 1
Chi-squared p-value: 0.5367435
the p-value may be wrong with some theoretical counts < 5
Chi-squared table:
obscounts theocounts
<= 0 10.000000 9.931706
<= 1 6.000000 6.952194
> 1 4.000000 3.116100
Goodness-of-fit criteria
1-mle-pois
Akaike's Information Criterion 45.53208
Bayesian Information Criterion 46.52781fit<-fitdist(srchscrlvce[srchscrlvce$Technique == "Voice",]$Errors,
"pois", discrete=TRUE)
gofstat(fit)Chi-squared statistic: 0.1611327
Degree of freedom of the Chi-squared distribution: 3
Chi-squared p-value: 0.9836055
the p-value may be wrong with some theoretical counts < 5
Chi-squared table:
obscounts theocounts
<= 3 5.000000 5.161546
<= 4 4.000000 3.473739
<= 5 3.000000 3.508476
<= 6 3.000000 2.952967
> 6 5.000000 4.903272
Goodness-of-fit criteria
1-mle-pois
Akaike's Information Criterion 84.19266
Bayesian Information Criterion 85.18839All three of the above goodness of fit tests tell us that there is no evidence of deviation from a Poisson distribution. Since we are now convinced of the Poisson distribution for each of the three techniques, analyze the errors using Poisson regression.
We’ve been saying “set sum-to-zero contrasts for the Anova call” but what does that mean? Contrasts are linear combinations used in ANOVA. As Wikipedia defines it, a contrast is a linear combination \(\sum^t_{i=1}a_i\theta_i\), where each \(\theta_i\) is a statistic and the \(a_i\) values sum to zero. Typically, the \(a_i\) values are \(1\) and \(-1\). A simple contrast represents a difference between means and is used in ANOVA. In R, they are invisible if you use Type I ANOVA, but have to be specified as follows if using a Type III ANOVA. The default anova() function is Type I but we’re using Type III, available from the Anova() function in the car package.
A minor detail is that we don’t really need to use Anova() here instead of anova() because the study is balanced, meaning that it has the same number of observations in each condition. The only reason for using Anova() on this data is that it gives a better-looking output. The anova() function would just display the \(\chi^2\) statistic without the associated \(p\)-value.
contrasts(srchscrlvce$Technique) <- "contr.sum"
#. family parameter identifies both distribution and link fn
m <- glm(Errors ~ Technique, data=srchscrlvce, family=poisson)
Anova(m, type=3)Analysis of Deviance Table (Type III tests)
Response: Errors
LR Chisq Df Pr(>Chisq)
Technique 74.93 2 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Because the Analysis of Deviance table shows a significant \(\chi^2\) value and corresponding \(p\)-value, we are justified to conduct pairwise comparisons among levels of Technique.
#. pacman::p_load(multcomp)
summary(glht(m, mcp(Technique="Tukey")), test=adjusted(type="holm"))
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: glm(formula = Errors ~ Technique, family = poisson, data = srchscrlvce)
Linear Hypotheses:
Estimate Std. Error z value Pr(>|z|)
Search - Scroll == 0 1.2730 0.3024 4.210 5.11e-05 ***
Voice - Scroll == 0 1.9761 0.2852 6.929 1.27e-11 ***
Voice - Search == 0 0.7031 0.1729 4.066 5.11e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- holm method)We see from the table that all three differences are significant. We could have guessed this result from glancing at the boxplot above, but it is valuable to have statistical evidence that this is not a chance difference.
13.11 More experiments without normally distributed errors (More generalized linear models)
13.11.1 Preference between touchpads vs trackballs by non / disabled people and males / females
This study examines whether participants of either sex with or without a disability prefer touchpads or trackballs. Start by examining the data and determining how many participants are involved.
dps <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/deviceprefssex.csv"))
dps$Subject<-as.factor(dps$Subject)
dps$Disability<-as.factor(dps$Disability)
dps$Sex<-as.factor(dps$Sex)
dps$Pref<-as.factor(dps$Pref)
summary(dps) Subject Disability Sex Pref
1 : 1 0:18 F:15 touchpad :21
2 : 1 1:12 M:15 trackball: 9
3 : 1
4 : 1
5 : 1
6 : 1
(Other):24 Use binomial regression to examine Pref by Disability and Sex. Report the \(p\)-value of the interaction of Disability\(\times\)Sex.
contrasts(dps$Disability) <- "contr.sum"
contrasts(dps$Sex) <- "contr.sum"
m<-glm(Pref ~ Disability*Sex, data=dps, family=binomial)
Anova(m, type=3)Analysis of Deviance Table (Type III tests)
Response: Pref
LR Chisq Df Pr(>Chisq)
Disability 10.4437 1 0.001231 **
Sex 2.8269 1 0.092695 .
Disability:Sex 0.6964 1 0.403997
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Now use multinomial regression for the same task and report the corresponding \(p\)-value.
#. pacman::p_load(nnet)
contrasts(dps$Disability) <- "contr.sum"
contrasts(dps$Sex) <- "contr.sum"
m<-multinom(Pref~Disability*Sex, data=dps)# weights: 5 (4 variable)
initial value 20.794415
iter 10 value 13.023239
iter 20 value 13.010200
final value 13.010184
convergedAnova(m, type=3)Analysis of Deviance Table (Type III tests)
Response: Pref
LR Chisq Df Pr(>Chisq)
Disability 10.4434 1 0.001231 **
Sex 2.8267 1 0.092710 .
Disability:Sex 0.6961 1 0.404087
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Now conduct post-hoc binomial tests for each Disability\(\times\)Sex combination.
m0<-binom.test(sum(dps[dps$Sex == "M" & dps$Disability == "0",]$Pref == "touchpad"),
nrow(dps[dps$Sex == "M" & dps$Disability == "0",]),p=1/2)
m1<-binom.test(sum(dps[dps$Sex == "M" & dps$Disability == "1",]$Pref == "touchpad"),
nrow(dps[dps$Sex == "M" & dps$Disability == "1",]),p=1/2)
f0<-binom.test(sum(dps[dps$Sex == "F" & dps$Disability == "0",]$Pref == "touchpad"),
nrow(dps[dps$Sex == "F" & dps$Disability == "0",]),p=1/2)
f1<-binom.test(sum(dps[dps$Sex == "F" & dps$Disability == "1",]$Pref == "touchpad"),
nrow(dps[dps$Sex == "F" & dps$Disability == "1",]),p=1/2)
p.adjust(c(m0$p.value, m1$p.value, f0$p.value,f1$p.value), method="holm")[1] 0.0625000 1.0000000 0.1962891 1.000000013.11.2 Handwriting recognition speed between different tools and right-handed vs left-handed people
This study examined three handwriting recognizers, A, B, and C and participants who are either right-handed or left-handed. The response is the number of incorrectly recognized handwritten words out of every 100 handwritten words. Examine the data and tell how many participants were involved.
hw <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/hwreco.csv"))
hw$Subject<-factor(hw$Subject)
hw$Recognizer<-factor(hw$Recognizer)
hw$Hand<-factor(hw$Hand)
summary(hw) Subject Recognizer Hand Errors
1 : 1 A:17 Left :25 Min. : 1.00
2 : 1 B:17 Right:25 1st Qu.: 3.00
3 : 1 C:16 Median : 4.00
4 : 1 Mean : 4.38
5 : 1 3rd Qu.: 6.00
6 : 1 Max. :11.00
(Other):44 Create an interaction plot of Recognizer on the \(x\)-axis and Hand as the traces and tell how many times the traces cross.
par(pin=c(2.75,1.25),cex=0.5)
with(hw,interaction.plot(Recognizer,Hand,Errors,
ylim=c(0,max(hw$Errors))))
Test whether the Errors of each Recognizer fit a Poisson distribution. First fit the Poisson distribution using fitdist(), then test the fit using gofstat(). The null hypothesis of this test is that the data do not deviate from a Poisson distribution.
#. pacman::p_load(fitdistrplus)
fit<-fitdist(hw[hw$Recognizer == "A",]$Errors,
"pois", discrete=TRUE)
gofstat(fit)Chi-squared statistic: 1.807852
Degree of freedom of the Chi-squared distribution: 2
Chi-squared p-value: 0.4049767
the p-value may be wrong with some theoretical counts < 5
Chi-squared table:
obscounts theocounts
<= 2 4.000000 3.627277
<= 3 5.000000 3.168895
<= 5 4.000000 6.072436
> 5 4.000000 4.131392
Goodness-of-fit criteria
1-mle-pois
Akaike's Information Criterion 75.86792
Bayesian Information Criterion 76.70113fit<-fitdist(hw[hw$Recognizer == "B",]$Errors,
"pois", discrete=TRUE)
gofstat(fit)Chi-squared statistic: 0.9192556
Degree of freedom of the Chi-squared distribution: 2
Chi-squared p-value: 0.6315187
the p-value may be wrong with some theoretical counts < 5
Chi-squared table:
obscounts theocounts
<= 3 5.000000 3.970124
<= 5 4.000000 5.800601
<= 6 3.000000 2.588830
> 6 5.000000 4.640444
Goodness-of-fit criteria
1-mle-pois
Akaike's Information Criterion 78.75600
Bayesian Information Criterion 79.58921fit<-fitdist(hw[hw$Recognizer == "C",]$Errors,
"pois", discrete=TRUE)
gofstat(fit)Chi-squared statistic: 0.3521272
Degree of freedom of the Chi-squared distribution: 2
Chi-squared p-value: 0.8385647
the p-value may be wrong with some theoretical counts < 5
Chi-squared table:
obscounts theocounts
<= 2 5.000000 4.600874
<= 3 4.000000 3.347372
<= 4 3.000000 3.085858
> 4 4.000000 4.965897
Goodness-of-fit criteria
1-mle-pois
Akaike's Information Criterion 70.89042
Bayesian Information Criterion 71.66301Now use Poisson regression to examine Errors by Recommender and Hand. Report the \(p\)-value for the Recognizer\(\times\)Hand interaction.
#. pacman::p_load(car)
contrasts(hw$Recognizer) <- "contr.sum"
contrasts(hw$Hand) <- "contr.sum"
m<-glm(Errors ~ Recognizer*Hand, data=hw, family=poisson)
Anova(m, type=3)Analysis of Deviance Table (Type III tests)
Response: Errors
LR Chisq Df Pr(>Chisq)
Recognizer 4.8768 2 0.087299 .
Hand 3.1591 1 0.075504 .
Recognizer:Hand 12.9682 2 0.001528 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Conduct planned comparisons between left and right errors for each recognizer. Using glht() and lsm() will give all comparisons and we only want three so don’t correct for multiple comparisons automatically. That would overcorrect. Instead, extract the three relevant \(p\)-values manually and and use p.adjust() to correct for those.
#. pacman::p_load(multcomp) # for glht
#. pacman::p_load(lsmeans) # for lsm
summary(glht(m, lsm(pairwise ~ Recognizer * Hand)),
test=adjusted(type="none"))
Simultaneous Tests for General Linear Hypotheses
Fit: glm(formula = Errors ~ Recognizer * Hand, family = poisson, data = hw)
Linear Hypotheses:
Estimate Std. Error z value Pr(>|z|)
A Left - B Left == 0 -8.938e-01 2.611e-01 -3.423 0.000619 ***
A Left - C Left == 0 -2.231e-01 3.000e-01 -0.744 0.456990
A Left - A Right == 0 -8.183e-01 2.638e-01 -3.102 0.001925 **
A Left - B Right == 0 -5.306e-01 2.818e-01 -1.883 0.059702 .
A Left - C Right == 0 -5.306e-01 2.818e-01 -1.883 0.059702 .
B Left - C Left == 0 6.707e-01 2.412e-01 2.780 0.005428 **
B Left - A Right == 0 7.551e-02 1.944e-01 0.388 0.697704
B Left - B Right == 0 3.632e-01 2.182e-01 1.665 0.095955 .
B Left - C Right == 0 3.632e-01 2.182e-01 1.665 0.095955 .
C Left - A Right == 0 -5.952e-01 2.441e-01 -2.438 0.014779 *
C Left - B Right == 0 -3.075e-01 2.635e-01 -1.167 0.243171
C Left - C Right == 0 -3.075e-01 2.635e-01 -1.167 0.243171
A Right - B Right == 0 2.877e-01 2.214e-01 1.299 0.193822
A Right - C Right == 0 2.877e-01 2.214e-01 1.299 0.193822
B Right - C Right == 0 3.331e-16 2.425e-01 0.000 1.000000
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- none method)p.adjust(c(0.001925,0.095955,0.243171),method="holm")[1] 0.005775 0.191910 0.243171The above analyses suggest that the error counts were Poisson-distributed. The above analyses suggest that there was a significant Recognizer\(\times\)Hand interaction. The above analyses suggest that for recognizer A, there were significantly more errors for right-handed participants than for left-handed participants.
13.11.3 Ease of booking international or domestic flights on three different services
This study describes flight bookings using one of three services, Expedia, Orbitz, or Priceline. Each booking was either International or Domestic and the Ease of each interaction was recorded on a 7 point Likert scale where 7 was easiest. Examine the data and determine the number of participants in the study.
bf <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/bookflights.csv"))
bf$Subject<-factor(bf$Subject)
bf$International<-factor(bf$International)
bf$Website<-factor(bf$Website)
bf$International<-factor(bf$International)
bf$Ease<-as.ordered(bf$Ease)
summary(bf) Subject Website International Ease
1 : 1 Expedia :200 0:300 1: 87
2 : 1 Orbitz :200 1:300 2: 58
3 : 1 Priceline:200 3:108
4 : 1 4:107
5 : 1 5: 95
6 : 1 6: 71
(Other):594 7: 74 Draw an interaction plot with Website on the x-axis and International as the traces. Determine how many times the traces cross.
par(pin=c(2.75,1.25),cex=0.5)
with(bf,interaction.plot(Website,International,as.numeric(Ease),
ylim=c(0,max(as.numeric(bf$Ease)))))
Use ordinal logistic regression to examine Ease by Website and International. Report the \(p\)-value of the Website main effect.
#. pacman::p_load(MASS) # provides polr()
#. pacman::p_load(car) # provides Anova()
#. set sum-to-zero contrasts for the Anova call
contrasts(bf$Website) <- "contr.sum"
contrasts(bf$International) <- "contr.sum"
m <- polr(Ease ~ Website*International, data=bf, Hess=TRUE)
Anova(m, type=3)Analysis of Deviance Table (Type III tests)
Response: Ease
LR Chisq Df Pr(>Chisq)
Website 6.811 2 0.03319 *
International 0.668 1 0.41383
Website:International 90.590 2 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Conduct three pairwise comparisons of Ease between domestic and international for each service. Report the largest adjusted \(p\)-value. Use the same technique as above where you extracted the relevant unadjusted \(p\)-values manually and used p.adjust() to adjust them.
summary(as.glht(pairs(lsmeans(m, pairwise ~ Website * International))),
test=adjusted(type="none"))
Simultaneous Tests for General Linear Hypotheses
Linear Hypotheses:
Estimate Std. Error
Expedia International0 - Orbitz International0 == 0 -2.1442 0.2619
Expedia International0 - Priceline International0 == 0 -0.9351 0.2537
Expedia International0 - Expedia International1 == 0 -1.6477 0.2570
Expedia International0 - Orbitz International1 == 0 -0.3217 0.2490
Expedia International0 - Priceline International1 == 0 -0.7563 0.2517
Orbitz International0 - Priceline International0 == 0 1.2091 0.2555
Orbitz International0 - Expedia International1 == 0 0.4965 0.2505
Orbitz International0 - Orbitz International1 == 0 1.8225 0.2571
Orbitz International0 - Priceline International1 == 0 1.3879 0.2546
Priceline International0 - Expedia International1 == 0 -0.7126 0.2518
Priceline International0 - Orbitz International1 == 0 0.6134 0.2497
Priceline International0 - Priceline International1 == 0 0.1789 0.2501
Expedia International1 - Orbitz International1 == 0 1.3260 0.2524
Expedia International1 - Priceline International1 == 0 0.8914 0.2506
Orbitz International1 - Priceline International1 == 0 -0.4345 0.2477
z value Pr(>|z|)
Expedia International0 - Orbitz International0 == 0 -8.189 2.22e-16 ***
Expedia International0 - Priceline International0 == 0 -3.686 0.000228 ***
Expedia International0 - Expedia International1 == 0 -6.411 1.44e-10 ***
Expedia International0 - Orbitz International1 == 0 -1.292 0.196380
Expedia International0 - Priceline International1 == 0 -3.004 0.002663 **
Orbitz International0 - Priceline International0 == 0 4.732 2.22e-06 ***
Orbitz International0 - Expedia International1 == 0 1.982 0.047498 *
Orbitz International0 - Orbitz International1 == 0 7.089 1.35e-12 ***
Orbitz International0 - Priceline International1 == 0 5.452 4.99e-08 ***
Priceline International0 - Expedia International1 == 0 -2.830 0.004659 **
Priceline International0 - Orbitz International1 == 0 2.457 0.014023 *
Priceline International0 - Priceline International1 == 0 0.715 0.474476
Expedia International1 - Orbitz International1 == 0 5.254 1.49e-07 ***
Expedia International1 - Priceline International1 == 0 3.557 0.000375 ***
Orbitz International1 - Priceline International1 == 0 -1.754 0.079408 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- none method)p.adjust(c(1.44e-10,1.35e-12,0.474476),method="holm")[1] 2.88000e-10 4.05000e-12 4.74476e-01The above analyses indicate a significant main effect of Website on Ease. The above analyses indicate a significant interaction between Website and International. Expedia was perceived as significantly easier for booking international flights than domestic flights. Orbitz, on the other hand, was perceived as significantly easier for booking domestic flights than international flights.
13.12 Same person using different tools (Within subjects studies)
13.12.1 Two search engines compared
ws <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/websearch2.csv"))How many subjects took part in this study?
ws$Subject<-factor(ws$Subject)
ws$Engine<-factor(ws$Engine)
summary(ws) Subject Engine Order Searches Effort
1 : 2 Bing :30 Min. :1.0 Min. : 89.0 Min. :1.00
2 : 2 Google:30 1st Qu.:1.0 1st Qu.:135.8 1st Qu.:2.00
3 : 2 Median :1.5 Median :156.5 Median :4.00
4 : 2 Mean :1.5 Mean :156.9 Mean :3.90
5 : 2 3rd Qu.:2.0 3rd Qu.:175.2 3rd Qu.:5.25
6 : 2 Max. :2.0 Max. :241.0 Max. :7.00
(Other):48 tail(ws)# A tibble: 6 × 5
Subject Engine Order Searches Effort
<fct> <fct> <dbl> <dbl> <dbl>
1 28 Google 2 131 4
2 28 Bing 1 192 4
3 29 Google 1 162 5
4 29 Bing 2 163 3
5 30 Google 2 146 5
6 30 Bing 1 137 2Thirty subjects participated.
What is the average number of searches for the engine with the largest average number of searches?
ws |>
group_by(Engine) |>
summarize(avg=mean(Searches))# A tibble: 2 × 2
Engine avg
<fct> <dbl>
1 Bing 166.
2 Google 148.Bing had 166 searches on average.
What is the \(p\)-value (four digits) from a paired-samples \(t\)-test of order effect?
#. pacman::p_load(reshape2)
ws.wide.order <- dcast(ws,Subject ~ Order, value.var="Searches")
tst<-t.test(ws.wide.order$"1",ws.wide.order$"2",paired=TRUE,var.equal=TRUE)
tst
Paired t-test
data: ws.wide.order$"1" and ws.wide.order$"2"
t = 0.34273, df = 29, p-value = 0.7343
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-13.57786 19.04453
sample estimates:
mean difference
2.733333 The \(p\)-value is 0.7343
What is the \(t\)-statistic (two digits) for a paired-samples \(t\)-test of Searches by Engine?
#. pacman::p_load(reshape2)
ws.wide.engine <- dcast(ws,Subject ~ Engine, value.var="Searches")
tst<-t.test(ws.wide.engine$"Bing",ws.wide.engine$"Google",paired=TRUE,var.equal=TRUE)
tst
Paired t-test
data: ws.wide.engine$Bing and ws.wide.engine$Google
t = 2.5021, df = 29, p-value = 0.01824
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
3.310917 32.955750
sample estimates:
mean difference
18.13333 The \(t\)-statistic is 2.50.
What is the \(p\)-value (four digits) from a Wilcoxon signed-rank test on Effort?
#. pacman::p_load(coin)
wilcoxsign_test(Effort~Engine|Subject,data=ws,distribution="exact")
Exact Wilcoxon-Pratt Signed-Rank Test
data: y by x (pos, neg)
stratified by block
Z = 0.68343, p-value = 0.5016
alternative hypothesis: true mu is not equal to 0The \(p\)-value is 0.5016.
13.12.2 Same but with three search engines
ws3 <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/websearch3.csv"))How many subjects took part in this study? ::: {.cell}
summary(ws3) Subject Engine Order Searches Effort
Min. : 1.0 Length:90 Min. :1 Min. : 92.0 Min. :1.000
1st Qu.: 8.0 Class :character 1st Qu.:1 1st Qu.:139.0 1st Qu.:3.000
Median :15.5 Mode :character Median :2 Median :161.0 Median :4.000
Mean :15.5 Mean :2 Mean :161.6 Mean :4.256
3rd Qu.:23.0 3rd Qu.:3 3rd Qu.:181.8 3rd Qu.:6.000
Max. :30.0 Max. :3 Max. :236.0 Max. :7.000 ws3$Subject<-as.factor(ws3$Subject)
ws3$Order<-as.factor(ws3$Order)
ws3$Engine<-as.factor(ws3$Engine)
tail(ws3)# A tibble: 6 × 5
Subject Engine Order Searches Effort
<fct> <fct> <fct> <dbl> <dbl>
1 29 Google 3 157 5
2 29 Bing 1 195 4
3 29 Yahoo 2 182 5
4 30 Google 3 152 1
5 30 Bing 2 188 7
6 30 Yahoo 1 131 3:::
Again, thirty subjects participated.
What is the average number of searches for the engine with the largest average number of searches?
plyr::ddply(ws3,~ Engine,summarize, Mean=mean(Searches)) Engine Mean
1 Bing 159.8333
2 Google 152.6667
3 Yahoo 172.4000Yahoo required 172.40 searches on average.
Find Mauchly’s \(W\) criterion (four digits) as a value of violation of sphericity.
pacman::p_load(ez)
m = ezANOVA(dv=Searches, within=Order, wid=Subject, data=ws3)
m$Mauchly Effect W p p<.05
2 Order 0.9416469 0.4309561 Mauchly’s \(W = 0.9416\), indicating that there is no violation of sphericity.
Conduct the appropriate ANOVA and give the \(p\)-value of the \(F\)-test (four digits).
m$ANOVA Effect DFn DFd F p p<.05 ges
2 Order 2 58 1.159359 0.320849 0.0278629The relevant \(p\)-value is 0.3208.
Conduct a repeated measures ANOVA on Searches by Engine and give the Mauchly’s \(W\) criterion (four digits).
#. pacman::p_load(ez)
m <- ezANOVA(dv=Searches, within=Engine, wid=Subject, data=ws3)
m$Mauchly Effect W p p<.05
2 Engine 0.9420316 0.4334278 Mauchly’s \(W = 0.9420\), indicating that there is no violation of sphericity.
Conduct the appropriate ANOVA and give the \(p\)-value of the \(F\)-test (four digits).
m$ANOVA Effect DFn DFd F p p<.05 ges
2 Engine 2 58 2.856182 0.06560302 0.06498641The relevant \(p\)-value is 0.0656.
Conduct post-hoc paired sample \(t\)-tests among levels of Engine, assuming equal variances and using “holm” to correct for multiple comparisons. What is the smallest \(p\)-value (four digits)? ::: {.cell}
#. pacman::p_load(reshape2)
ws3.wide.engine <- dcast(ws3,Subject~Engine,value.var="Searches")
bi.go<-t.test(ws3.wide.engine$Bing,ws3.wide.engine$Google,paired=TRUE,var.equal=TRUE)
bi.ya<-t.test(ws3.wide.engine$Bing,ws3.wide.engine$Yahoo,paired=TRUE,var.equal=TRUE)
go.ya<-t.test(ws3.wide.engine$Google,ws3.wide.engine$Yahoo,paired=TRUE,var.equal=TRUE)
p.adjust(c(bi.go$p.value,bi.ya$p.value,go.ya$p.value),method="holm")[1] 0.37497103 0.37497103 0.05066714::: The smallest \(p\)-value is 0.0507.
Conduct a Friedman (nonparametric) test on Effort. Find the \(\chi^2\) statistic (four digits).
#. pacman::p_load(coin)
friedman_test(Effort~Engine|Subject,data=ws3,distribution="asymptotic")
Asymptotic Friedman Test
data: Effort by
Engine (Bing, Google, Yahoo)
stratified by Subject
chi-squared = 8.0182, df = 2, p-value = 0.01815\(\chi^2=8.0182\)
Conduct post hoc pairwise Wilcoxon signed-rank tests on Effort by Engine with “holm” for multiple comparison correction. Give the smallest \(p\)-value (four digits).
#. pacman::p_load(reshape2)
ws3.wide.effort <- dcast(ws3,Subject~Engine,value.var="Effort")
bi.go<-wilcox.test(ws3.wide.effort$Bing,ws3.wide.effort$Google,paired=TRUE,exact=FALSE)
bi.ya<-wilcox.test(ws3.wide.effort$Bing,ws3.wide.effort$Yahoo,paired=TRUE,exact=FALSE)
go.ya<-wilcox.test(ws3.wide.effort$Google,ws3.wide.effort$Yahoo,paired=TRUE,exact=FALSE)
p.adjust(c(bi.go$p.value,bi.ya$p.value,go.ya$p.value),method="holm")[1] 0.69319567 0.03085190 0.04533852The smallest \(p\)-value is 0.0309.
13.13 Experiments with people in groups doing tasks with different tools (Mixed models)
Mixed models contain both fixed effects and random effects. Following are linear mixed models and generalized linear mixed models examples. Recall that linear models have normally distributed residuals while generalized linear models may have residuals following other distributions.
13.13.1 Searching to find facts and effort of searching (A linear mixed model)
Load websearch3.csv. It describes a test of the number of searches required to find out a hundred facts and the perceived effort of searching. How many subjects participated?
ws <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/websearch3.csv"))
ws<-within(ws,Subject<-factor(Subject))
ws<-within(ws,Order<-factor(Order))
ws<-within(ws,Engine<-factor(Engine))
tail(ws)# A tibble: 6 × 5
Subject Engine Order Searches Effort
<fct> <fct> <fct> <dbl> <dbl>
1 29 Google 3 157 5
2 29 Bing 1 195 4
3 29 Yahoo 2 182 5
4 30 Google 3 152 1
5 30 Bing 2 188 7
6 30 Yahoo 1 131 3summary(ws) Subject Engine Order Searches Effort
1 : 3 Bing :30 1:30 Min. : 92.0 Min. :1.000
2 : 3 Google:30 2:30 1st Qu.:139.0 1st Qu.:3.000
3 : 3 Yahoo :30 3:30 Median :161.0 Median :4.000
4 : 3 Mean :161.6 Mean :4.256
5 : 3 3rd Qu.:181.8 3rd Qu.:6.000
6 : 3 Max. :236.0 Max. :7.000
(Other):72 What was the average number of Search instances for each Engine?
ws |>
group_by(Engine) |>
summarize(median=median(Searches),
avg=mean(Searches),
sd=sd(Searches))# A tibble: 3 × 4
Engine median avg sd
<fct> <dbl> <dbl> <dbl>
1 Bing 162. 160. 30.6
2 Google 152 153. 24.6
3 Yahoo 170. 172. 37.8plyr::ddply(ws,~Engine,summarize,avg=mean(Searches)) Engine avg
1 Bing 159.8333
2 Google 152.6667
3 Yahoo 172.4000Conduct a linear mixed model analysis of variance on Search by Engine and report the \(p\)-value.
pacman::p_load(lme4) # for lmer
pacman::p_load(lmerTest)
#. pacman::p_load(car) # for Anova
contrasts(ws$Engine) <- "contr.sum"
m <- lmer(Searches ~ Engine + (1|Subject), data=ws)boundary (singular) fit: see help('isSingular')Anova(m, type=3, test.statistic="F")Analysis of Deviance Table (Type III Wald F tests with Kenward-Roger df)
Response: Searches
F Df Df.res Pr(>F)
(Intercept) 2374.8089 1 29 < 2e-16 ***
Engine 3.0234 2 58 0.05636 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Conduct simultaneous pairwise comparisons among all levels of Engine, despite the previous \(p\)-value. Report the adjusted(by Holm’s sequential Bonferroni procedure) \(p\)-values.
#. pacman::p_load(multcomp)
summary(glht(m, mcp(Engine="Tukey")),
test=adjusted(type="holm")) # Tukey means compare all pairs
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: lmer(formula = Searches ~ Engine + (1 | Subject), data = ws)
Linear Hypotheses:
Estimate Std. Error z value Pr(>|z|)
Google - Bing == 0 -7.167 8.124 -0.882 0.3777
Yahoo - Bing == 0 12.567 8.124 1.547 0.2438
Yahoo - Google == 0 19.733 8.124 2.429 0.0454 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- holm method)
13.13.4 Finding number of unique words used in posts by males and females (A generalized linear mixed model)
The file vocab.csv describes a study in which 50 posts by males and females were analyzed for the number of unique words used. Load the file and tell the number of participants.
vo <- read_csv(paste0(Sys.getenv("STATS_DATA_DIR"),"/vocab.csv"))
vo<-within(vo,Subject<-factor(Subject))
vo<-within(vo,Sex<-factor(Sex))
vo<-within(vo,Order<-factor(Order))
vo<-within(vo,Social<-factor(Social))
tail(vo)# A tibble: 6 × 5
Subject Sex Social Order Vocab
<fct> <fct> <fct> <fct> <dbl>
1 29 M Facebook 3 46
2 29 M Twitter 1 38
3 29 M Gplus 2 22
4 30 F Facebook 3 103
5 30 F Twitter 2 97
6 30 F Gplus 1 92Create an interaction plot and see how often the lines cross.
par(pin=c(2.75,1.25),cex=0.5)
with(vo,interaction.plot(Social,Sex,Vocab,ylim=c(0,max(vo$Vocab))))
Perform Kolmogorov-Smirnov goodness-of-fit tests on Vocab for each level of Social using exponential distributions.
#. pacman::p_load(MASS)
fit = fitdistr(vo[vo$Social == "Facebook",]$Vocab, "exponential")$estimate
ks.test(vo[vo$Social == "Facebook",]$Vocab, "pexp", rate=fit[1], exact=TRUE)Warning in ks.test.default(vo[vo$Social == "Facebook", ]$Vocab, "pexp", : ties
should not be present for the Kolmogorov-Smirnov test
Exact one-sample Kolmogorov-Smirnov test
data: vo[vo$Social == "Facebook", ]$Vocab
D = 0.17655, p-value = 0.2734
alternative hypothesis: two-sidedfit = fitdistr(vo[vo$Social == "Twitter",]$Vocab, "exponential")$estimate
ks.test(vo[vo$Social == "Twitter",]$Vocab, "pexp", rate=fit[1], exact=TRUE)Warning in ks.test.default(vo[vo$Social == "Twitter", ]$Vocab, "pexp", rate =
fit[1], : ties should not be present for the Kolmogorov-Smirnov test
Exact one-sample Kolmogorov-Smirnov test
data: vo[vo$Social == "Twitter", ]$Vocab
D = 0.099912, p-value = 0.8966
alternative hypothesis: two-sidedfit = fitdistr(vo[vo$Social == "Gplus",]$Vocab, "exponential")$estimate
ks.test(vo[vo$Social == "Gplus",]$Vocab, "pexp", rate=fit[1], exact=TRUE)
Exact one-sample Kolmogorov-Smirnov test
data: vo[vo$Social == "Gplus", ]$Vocab
D = 0.14461, p-value = 0.5111
alternative hypothesis: two-sidedUse a generallized linear mixed model to conduct a test of order effects on Vocab.
contrasts(vo$Sex) <- "contr.sum"
contrasts(vo$Order) <- "contr.sum"
m <- glmer(Vocab ~ Sex*Order + (1|Subject), data=vo, family=Gamma(link="log"))
Anova(m, type=3)Analysis of Deviance Table (Type III Wald chisquare tests)
Response: Vocab
Chisq Df Pr(>Chisq)
(Intercept) 1179.0839 1 <2e-16 ***
Sex 1.3687 1 0.2420
Order 0.7001 2 0.7047
Sex:Order 2.0655 2 0.3560
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Conduct a test of Vocab by Sex and Social using a generalized linear mixed model.
contrasts(vo$Sex) <- "contr.sum"
contrasts(vo$Social) <- "contr.sum"
m = glmer(Vocab ~ Sex*Social + (1|Subject), data=vo, family=Gamma(link="log"))
Anova(m, type=3)Analysis of Deviance Table (Type III Wald chisquare tests)
Response: Vocab
Chisq Df Pr(>Chisq)
(Intercept) 1172.6022 1 < 2.2e-16 ***
Sex 0.7925 1 0.3733
Social 26.2075 2 2.038e-06 ***
Sex:Social 0.3470 2 0.8407
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Perform post hoc pairwise comparisons among levels of Social adjusted with Holm’s sequential Bonferroni procedure.
#. pacman::p_load(multcomp)
summary(glht(m, mcp(Social="Tukey")),
test=adjusted(type="holm")) # Tukey means compare all pairsWarning in mcp2matrix(model, linfct = linfct): covariate interactions found --
default contrast might be inappropriate
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: glmer(formula = Vocab ~ Sex * Social + (1 | Subject), data = vo,
family = Gamma(link = "log"))
Linear Hypotheses:
Estimate Std. Error z value Pr(>|z|)
Gplus - Facebook == 0 0.8676 0.2092 4.148 6.72e-05 ***
Twitter - Facebook == 0 -0.1128 0.2026 -0.556 0.578
Twitter - Gplus == 0 -0.9803 0.2071 -4.734 6.60e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- holm method)13.13.5 Judging search effort among different search engines (Another generalized linear mixed model)
Recode Effort from websearch3.csv as an ordinal response.
ws<-within(ws,Effort<-factor(Effort))
ws<-within(ws,Effort<-ordered(Effort))
summary(ws) Subject Engine Order Searches Effort
1 : 3 Bing :30 1:30 Min. : 92.0 1: 6
2 : 3 Google:30 2:30 1st Qu.:139.0 2: 8
3 : 3 Yahoo :30 3:30 Median :161.0 3:19
4 : 3 Mean :161.6 4:16
5 : 3 3rd Qu.:181.8 5:16
6 : 3 Max. :236.0 6:15
(Other):72 7:10 Conduct an ordinal logistic regression to determine Effort by Engine, using a generalized linear mixed model.
pacman::p_load(ordinal) # provides clmm
#. pacman::p_load(RVAideMemoire) # provides Anova.clmm
ws2<-data.frame(ws)
m<-clmm(Effort~Engine + (1|Subject),data=ws2)
Anova.clmm(m,type=3)Analysis of Deviance Table (Type III tests)
Response: Effort
LR Chisq Df Pr(>Chisq)
Engine 8.102 2 0.0174 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Perform pairwise comparisons of Engine on Effort.
par(pin=c(2.75,1.25),cex=0.5)
plot(as.numeric(Effort) ~ Engine,data=ws2)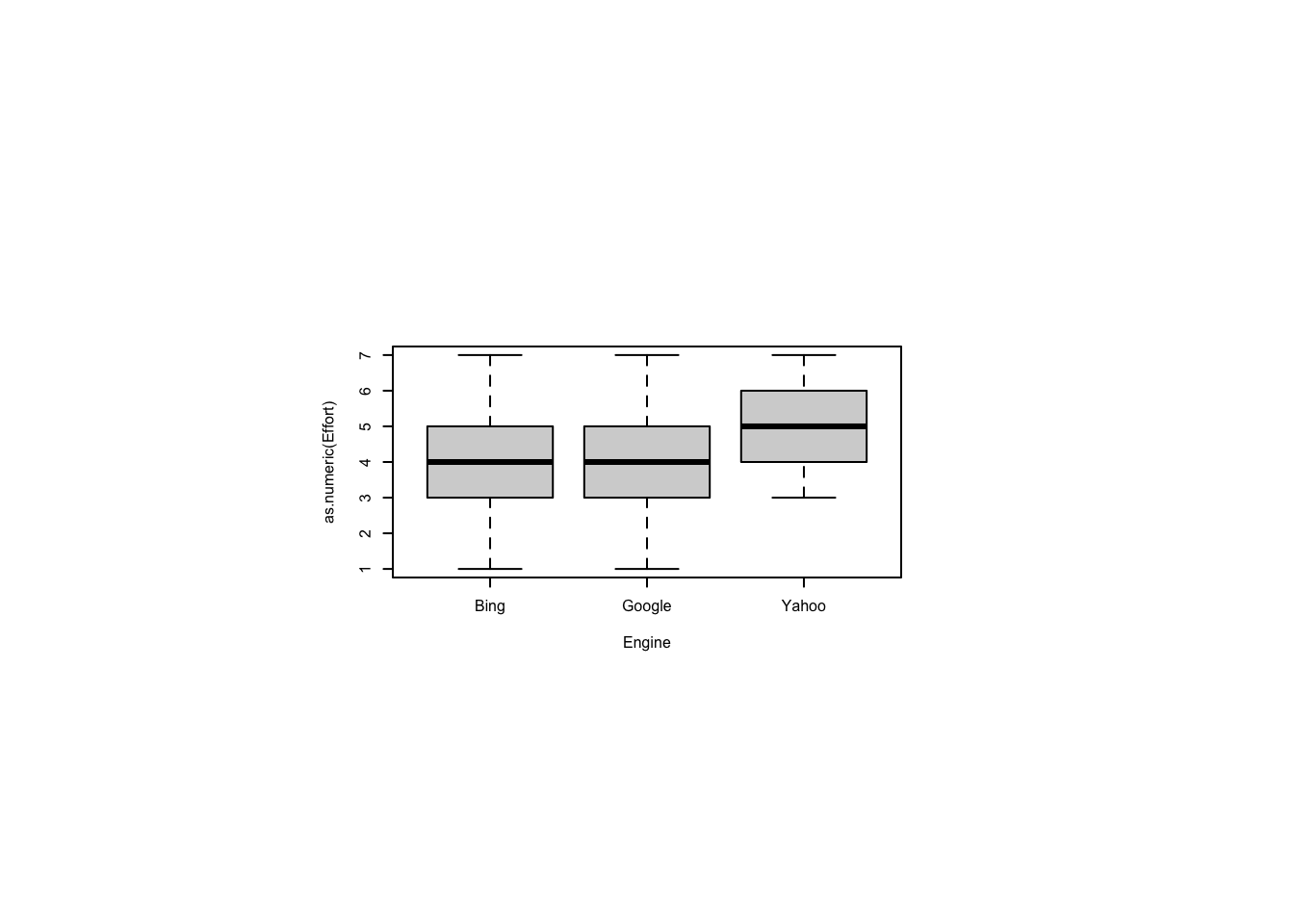
#. pacman::p_load(lme4)
#. pacman::p_load(multcomp)
m <- lmer(as.numeric(Effort)~Engine + (1|Subject), data=ws2)boundary (singular) fit: see help('isSingular')summary(glht(m,mcp(Engine="Tukey")),test=adjusted(type="holm"))
Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts
Fit: lmer(formula = as.numeric(Effort) ~ Engine + (1 | Subject), data = ws2)
Linear Hypotheses:
Estimate Std. Error z value Pr(>|z|)
Google - Bing == 0 -0.03333 0.42899 -0.078 0.9381
Yahoo - Bing == 0 1.10000 0.42899 2.564 0.0247 *
Yahoo - Google == 0 1.13333 0.42899 2.642 0.0247 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Adjusted p values reported -- holm method)
13.9.3 Social media value judged by people after watching clips (two-by-two within subject design)
The file socialvalue.csv describes a study of people viewing a pos or neg film clip then going onto social media and judging the value of the first 100 posts they see. The number of valued posts was recorded. What kind of experimental design is this? [Answer: A \(2\times 2\) within-subject design with factors for Clip (positive, negative) and Social (Facebook, Twitter).]
What’s the average number of valued posts for the most valued combination of Clip and Social?
Create an interaction plot with Social on the \(X\)-Axis and Clip as the traces. Do the lines cross? Do the same for reversed axes.
Test for an order effect in the presentation of order of the ClipOrder or SocialOrder factor. Report the \(p\)-values.
Conduct a factorial ANOVA on Valued by Clip and Social. Report the largest \(F\)-statistic.
Conduct paired-samples \(t\)-tests to answer two questions. First, on Facebook, were the number of valued posts different after watching a positive or negative clip. Second, same on Twitter. Assume equal variances and use Holm’s sequential Bonferroni procedure to correct for multiple comparisons. Report the lowest adjusted \(p\)-value.
Conduct a nonparametric Aligned Rank Transform Procedure on Valued by Clip and Social.
Conduct interaction contrasts to discover whether the difference on Facebook was itself different from the difference on Twitter. Report the \(\chi^2\) statistic.