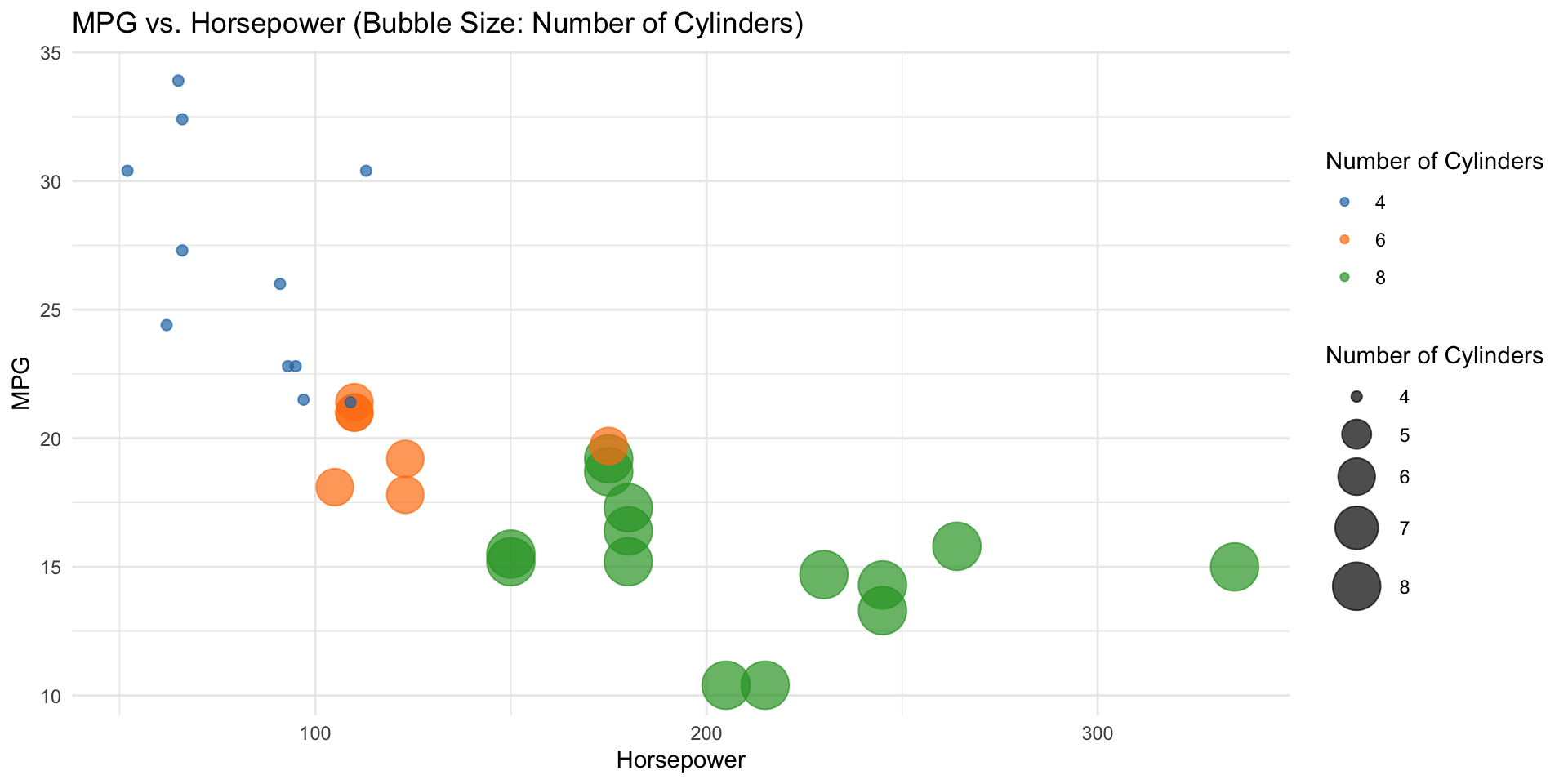
Note that R allows you to assign names to rows of a dataframe just as you can assign names to columns of a dataframe. We saw an example of that with the mtcars data, which appeared to have an extra column because the car makes and models were assigned as rownames.
Mean
arithmetic mean is the most popular measure of centrality
can be dragged away from the center by outliers
can be found by mean(vectorname) in R if vector is numeric
can find all means in dataframe with colMeans(df) or sapply(df,mean)
Means of some, but not all, columns
subsetting just the first, second, and fourth column colMeans(mtcars[,c(1,2:4)])